Nvidia loses US$600 billion in a day after Chinese startup DeepSeek reveals a cheap AI model
Nvidia recorded the largest single-day loss in stock market history after Chinese startup DeepSeek released its own reasoning AI model.
 Astrong
Astrong

Disclaimer: Unless otherwise stated, any opinions expressed below belong solely to the author.
History was written anew yesterday when one of the currently most valuable companies in the world and biggest winners of the AI rally, American GPU maker Nvidia, recorded the largest single-day loss in stock market history—US$589 billion wiped out in a single day.
The collapse pushed it below the US$3 trillion market capitalisation and has investors questioning the future of artificial intelligence (AI) investment.
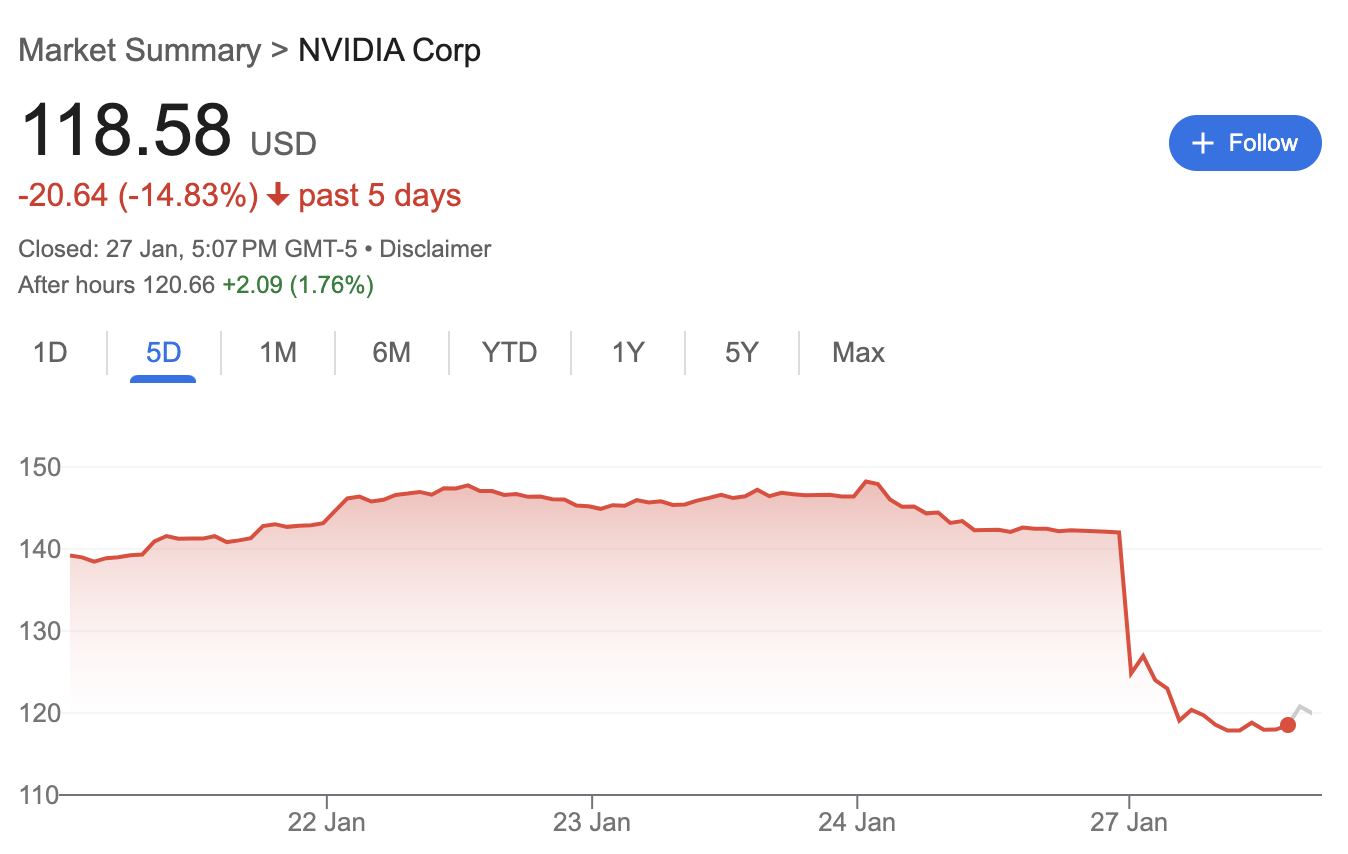 Nvidia’s stock fell off a cliff after the markets opened on Monday. / Image Credit: Google
Nvidia’s stock fell off a cliff after the markets opened on Monday. / Image Credit: GoogleAll of this turmoil was caused by a Chinese startup, DeepSeek. Founded less than two years ago, DeepSeek has just released its own reasoning AI model, the R1, which has matched OpenAI’s current top offering, the “o1.”
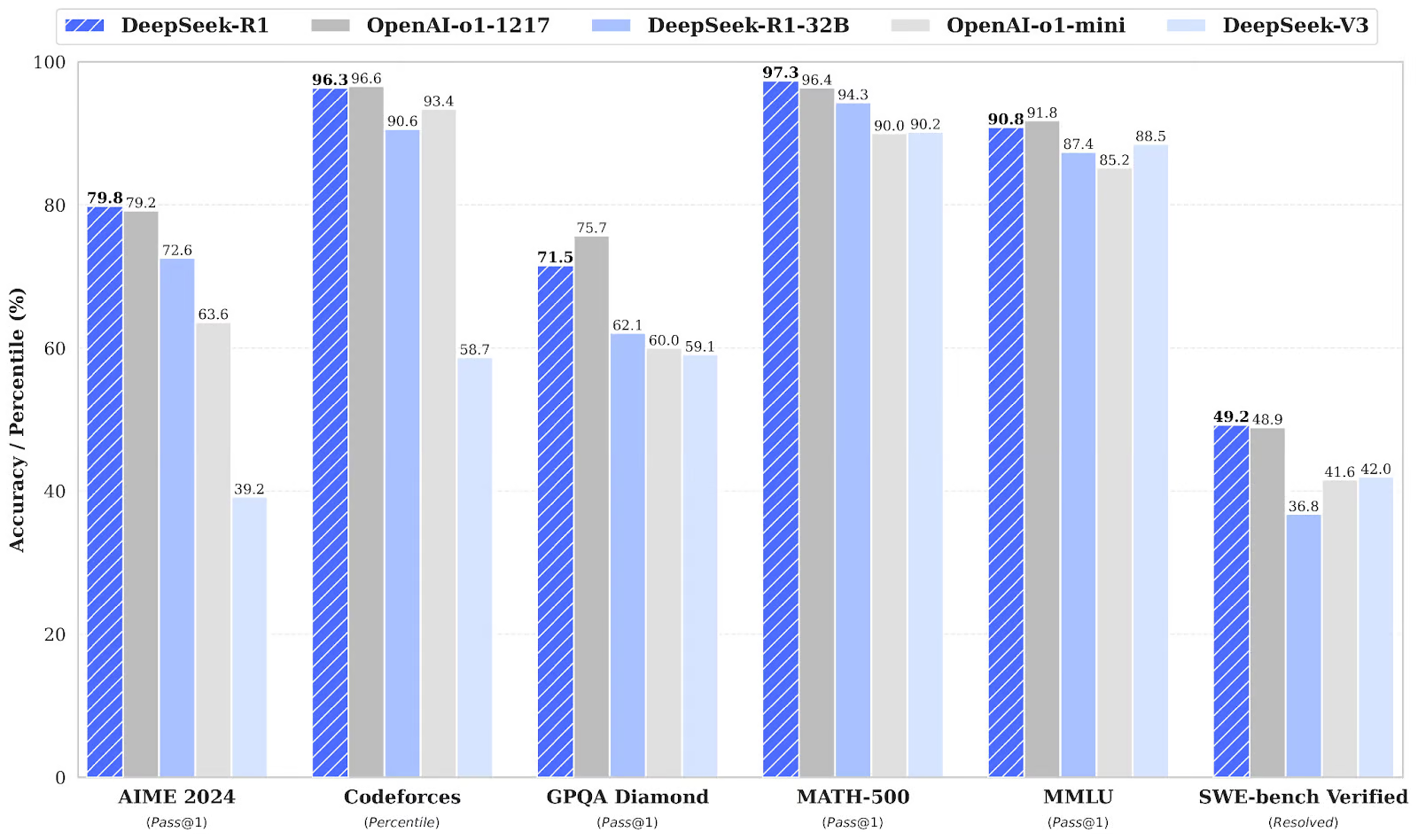 R1 performs roughly on par with OpenAI’s o1 model in AI benchmarks. / ImageCredit: DeepSeek.
R1 performs roughly on par with OpenAI’s o1 model in AI benchmarks. / ImageCredit: DeepSeek.The news sent American tech stocks, including Nvidia, into free fall, and the reason behind this is that the model was reportedly developed at a cost of just US$5.6 million in computing expenses—a pittance compared to the tens of billions of dollars spent by OpenAI, Google, Microsoft and others.
OpenAI alone was projected to spend around US$7 billion on just training last year, and yet, it has been blown out of the water by a little-known Chinese garage band startup that has yet to celebrate its second birthday.
As if that wasn’t enough, the company is said to have used just a paltry 2,048 of the less powerful Nvidia H800 GPUs, reportedly acquired before sanctions on exports to China have been imposed. This starkly contrasts with hundreds of thousands of the most advanced Nvidia cards snapped up at the expense of billions of dollars by Silicon Valley giants competing in the global AI race.
As a result, it’s also much cheaper to use, charging just US$0.14 per 1 million input tokens compared to OpenAI’s US$15.
DeepSeek’s models are also open-source, meaning that anybody can download them and use them on-premises in full control of their data, as opposed to proprietary services like the ones provided by OpenAI.
It’s no surprise, then, that the holders of Nvidia’s stock are worried about the future of the company’s record-breaking sales, spooking thousands of them if they are safe and offloading their holdings in those companies, just in case AI turns out to be a bubble about to burst.
Too good to be true?
In this spirit, Morningstar’s chief US market strategist quipped that “people are selling first and will ask questions later.” So, Nvidia’s massive drop in value should not be overly exaggerated.
It’s not impossible, of course, that we may be witnessing a true breakthrough moment as happened in the past, especially with restricted access to the latest hardware.
Necessity is the mother of invention, and perhaps, given the export restrictions placed on cutting-edge hardware designed by American companies, ambitious Chinese competitors felt forced to seek clever alternatives that the big spenders didn’t think of.
However, it may also be possible—given the scale of the reported leap—that we’re not being told everything.
There are some cracks in the story showing already. Scale AI’s founder and CEO, Alexandr Wang, has suggested that Chinese companies have managed to build AI clusters comprising thousands of advanced Nvidia H100 GPUs.
You know the Chinese labs, they have more H100s than people think. The understanding is that DeepSeek has about fifty thousand H100s. […] They can’t talk about obviously because it is against the export controls that United States has put in place.
Alexandr WangEven with the alleged 50,000 H100s, DeepSeek’s achievement would be very impressive but nowhere near the supposed 2,000 H800s. It would also prove that Nvidia’s hardware is still essential.
But the opacity surrounding the hardware stack isn’t the only question mark—the methodology is as well, including DeepSeek’s reliance on competitor models.
Nvidia itself has put out a statement addressing the topic, smuggling a reference to this particular subject in it:
DeepSeek is an excellent AI advancement and a perfect example of Test Time Scaling. DeepSeek’s work illustrates how new models can be created using that technique, leveraging widely-available models and compute that is fully export control compliant. Inference requires significant numbers of NVIDIA GPUs and high-performance networking. We now have three scaling laws: pre-training and post-training, which continue, and new test-time scaling.
NvidiaBut what does it mean?
R1 calls itself… ChatGPT
As reported by at least several users here, here and here, the Chinese chatbot claims to be ChatGPT or that it has to adhere to “OpenAI policies.”
 Smoking gun? / Image credit: Reddit
Smoking gun? / Image credit: RedditThis suggests that it was directly trained on OpenAI’s models, probably by feeding queries through them to produce synthetic data for its own training.
What this means is that it’s quite likely that its prowess was achieved by learning from the responses provided by, e.g. o1, while the “chain of thought” process introduced in that model by OpenAI was fairly easy to reverse engineer on top of it.
It’s really like cheating on an exam or merely repeating what your better-prepared colleague says.

What that could mean, essentially, is that while Silicon Valley spent billions on data centres and training, a small upstart came and simply asked the leading bots to provide the answers, accelerating the training of its “own” model.
This would explain why R1 matches but does not outperform OpenAI’s “o1,” especially as the company is about to launch the full “o3,” which has already vastly outperformed its younger sibling.
In other words, it is highly likely that R1 simply learned from competitors who have performed the necessary training on hundreds of thousands of Nvidia GPUs, without which none of this would have been possible.
However, this does raise some questions about the future of AI investment, though.
If smaller companies can simply train their own models using replies provided by expensive, proprietary competitors and then release them as open-source or sell access to them at a fraction of the cost, who is going to keep investing large sums of money on fundamental training and research?
Controlling or capping access to a chatbot like ChatGPT may either be impossible, given the huge volume of queries it already handles on behalf of OpenAI’s various customers, or be an impediment, at most slowing down such attempts but not eliminating them completely.
It also shows that even if the US restricts access to hardware, China can still learn from the outputs alone.
Many questions need answering, and it’s quite likely that the coming days will reveal more about the nature of R1’s surprising performance.
Featured image: MuhammadAlimaki / depositphotos