React SEO: Best Practices to Make It SEO-Friendly
React and other similar libraries (like Vue.js) are becoming the de facto choice for larger businesses that require complex development where a more simplistic approach (like using a WordPress theme) won’t satisfy the requirements. Despite that, SEOs did not initially embrace libraries...
 Tfoso
Tfoso

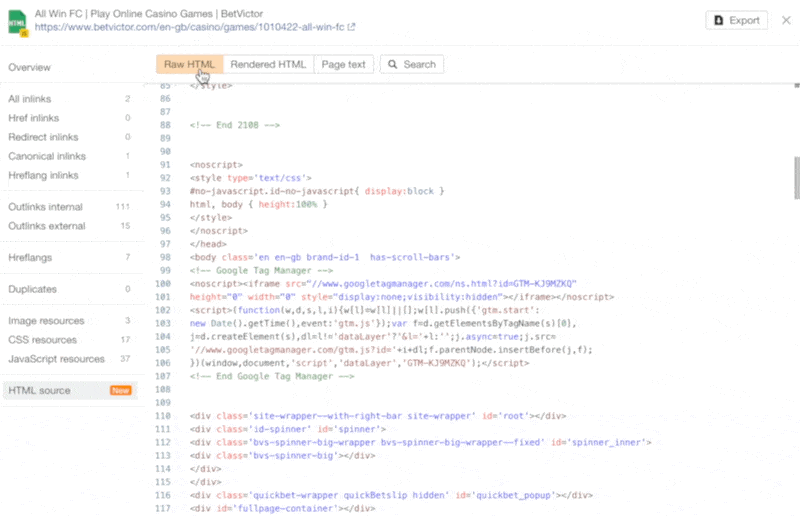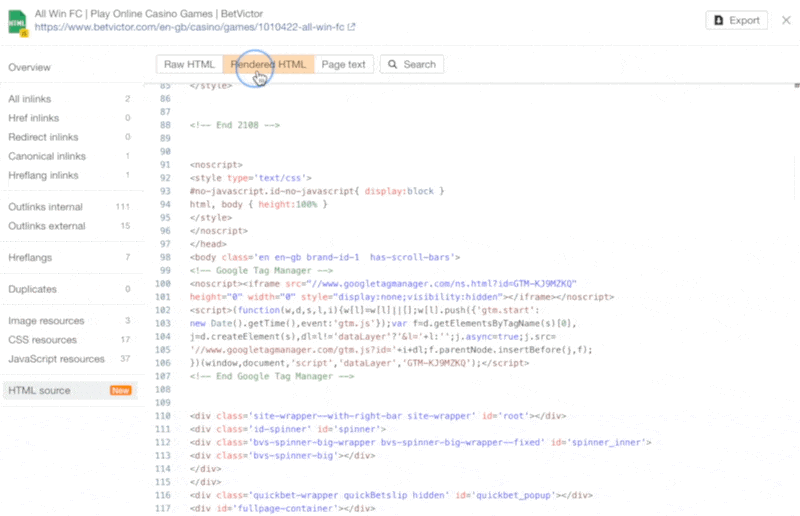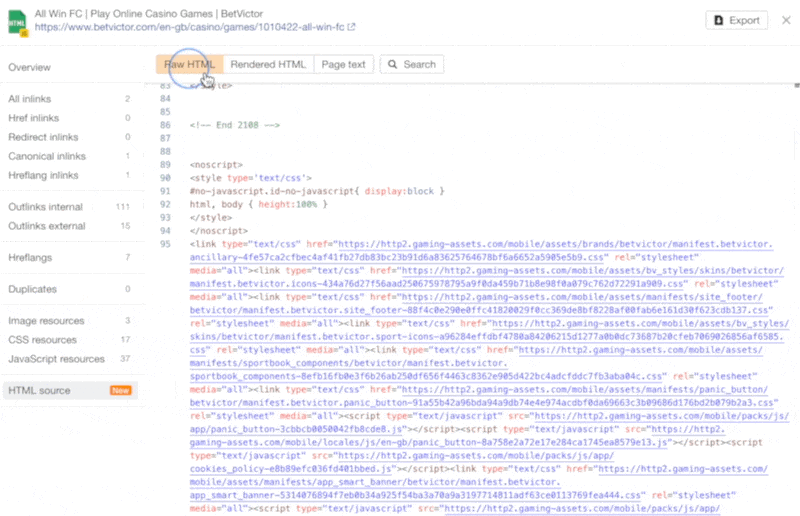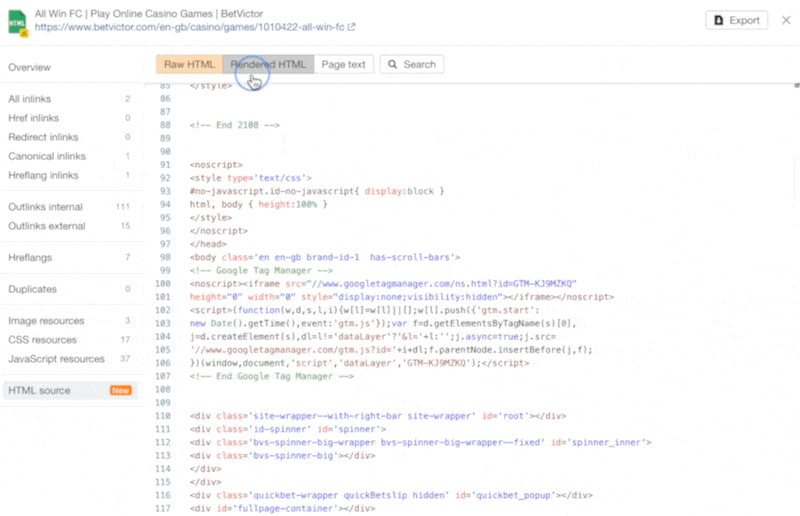
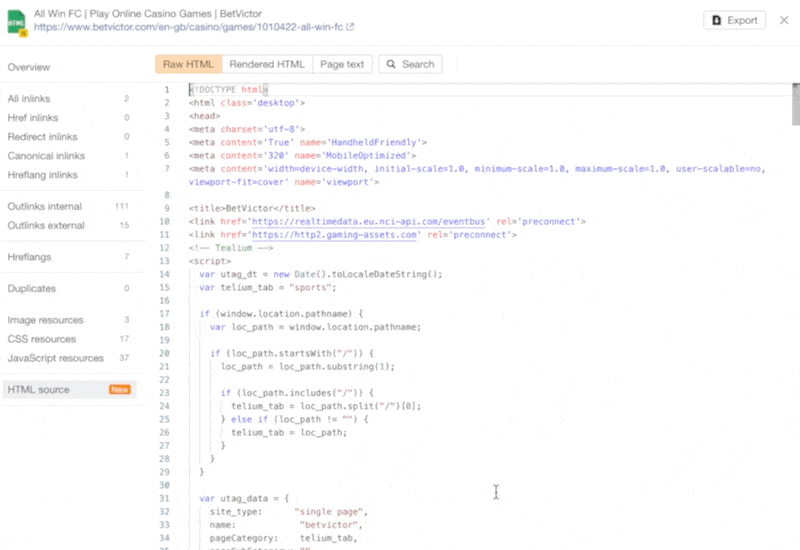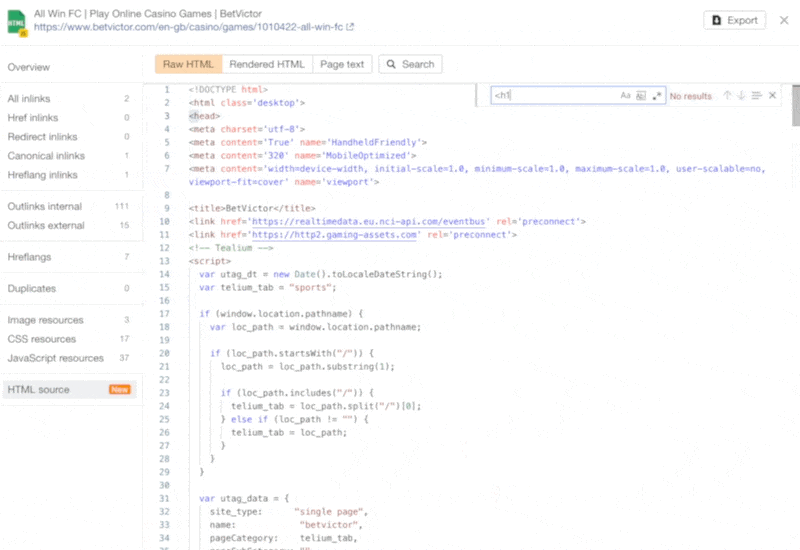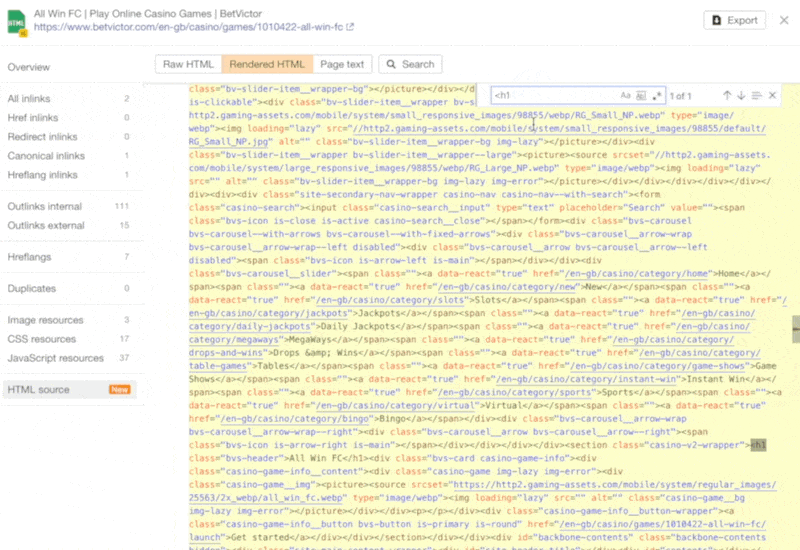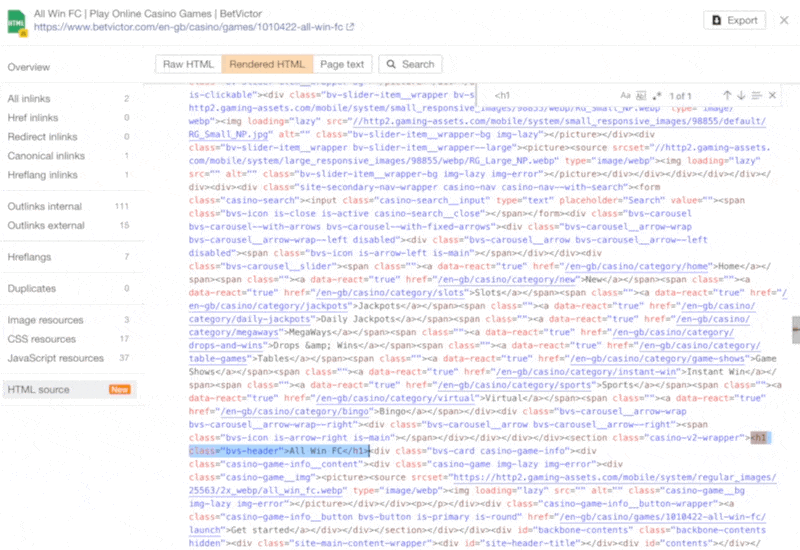
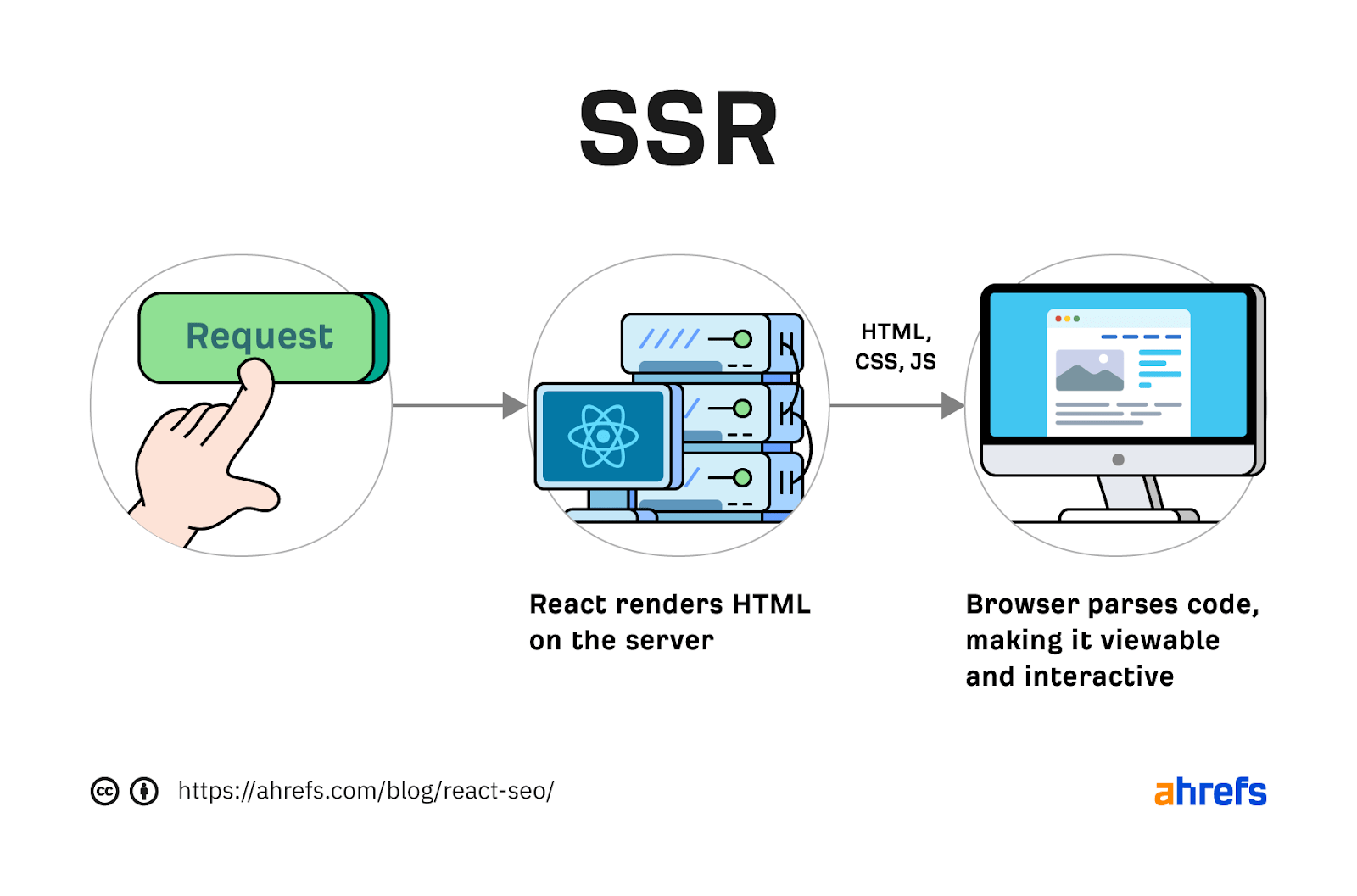
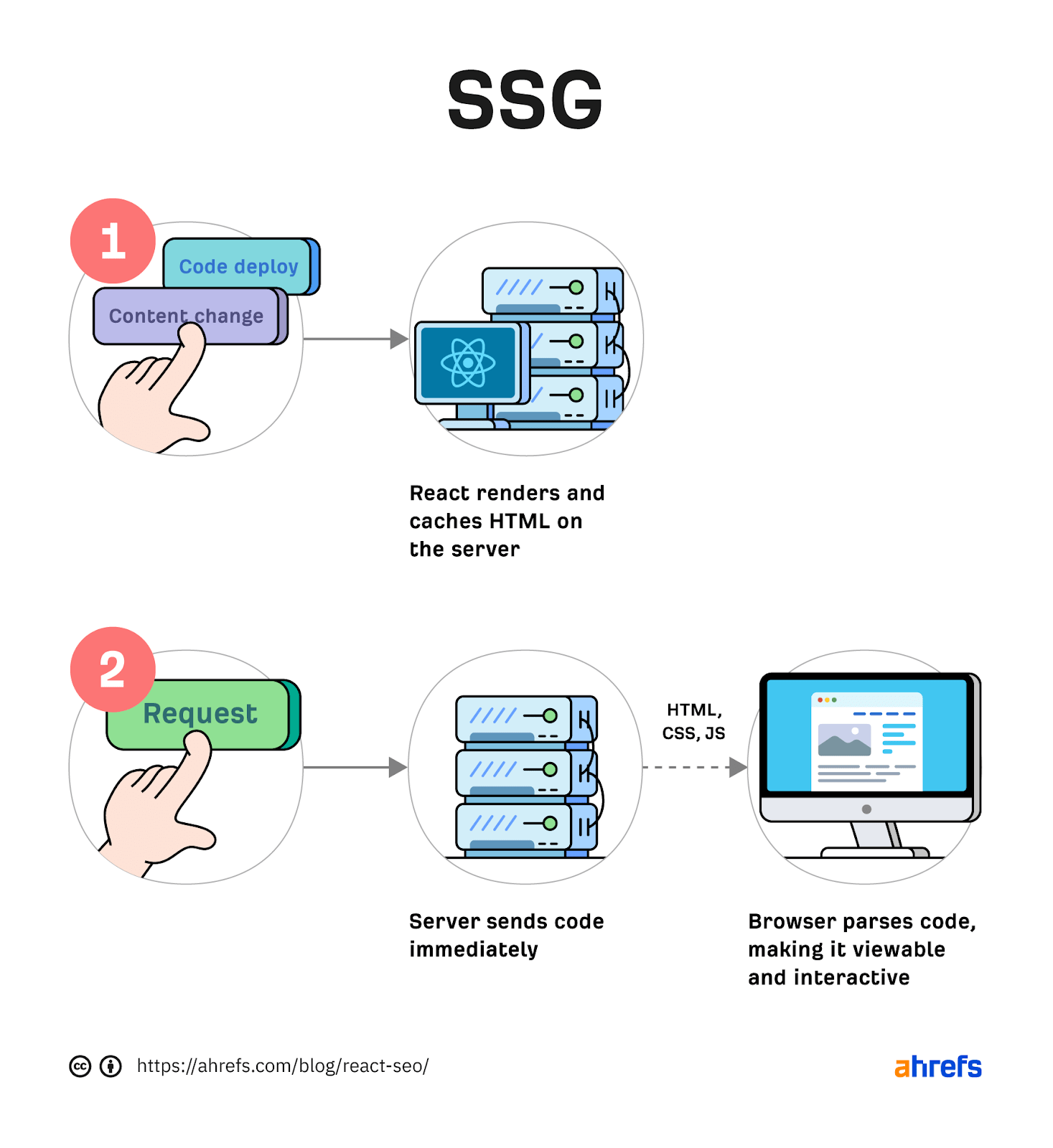
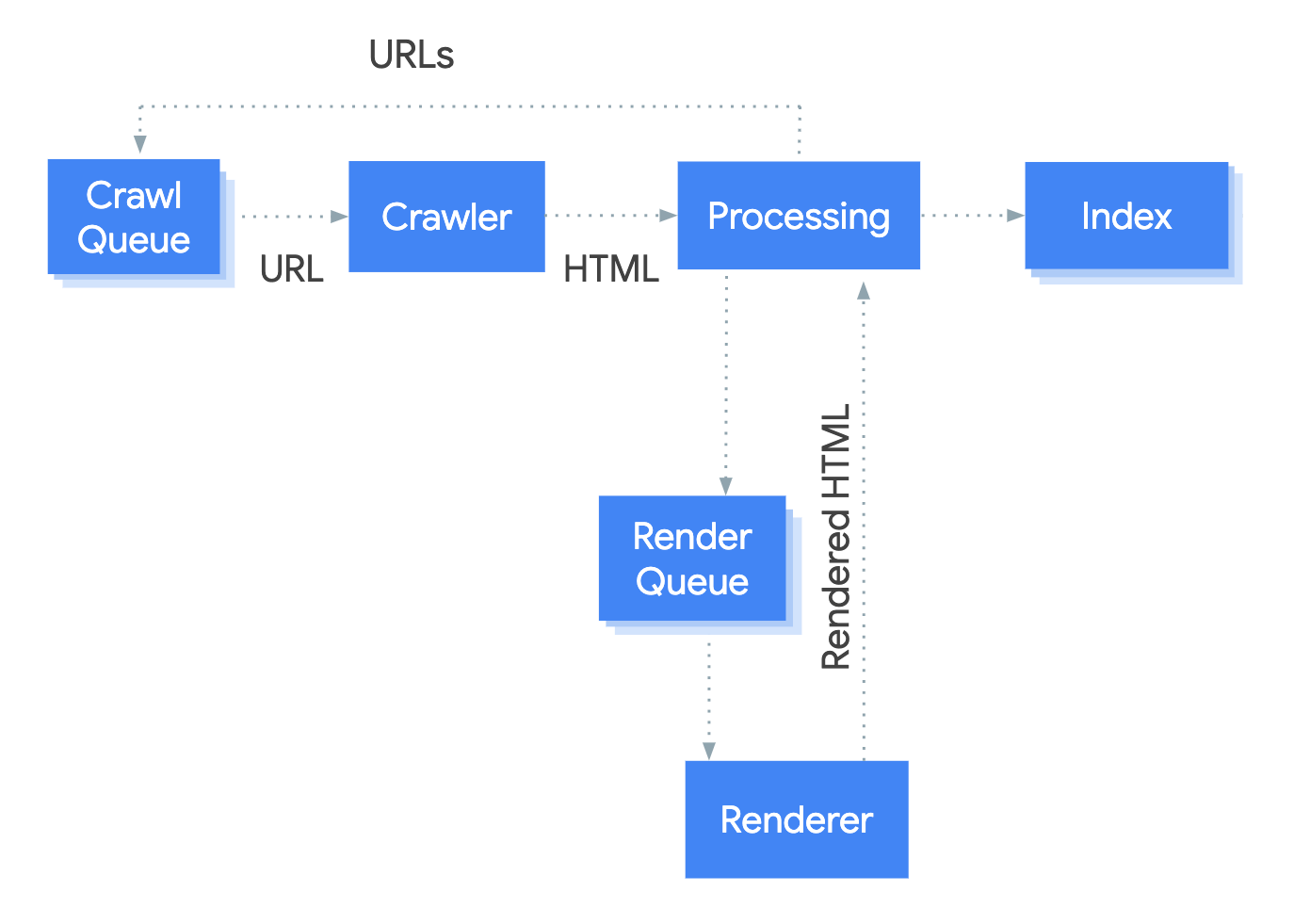
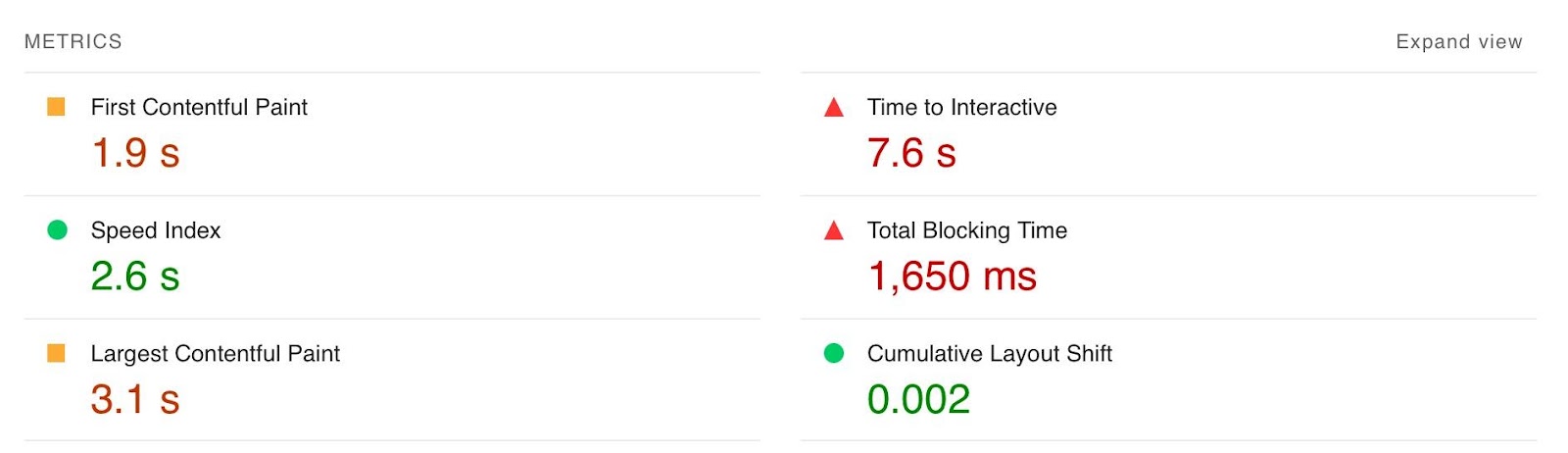
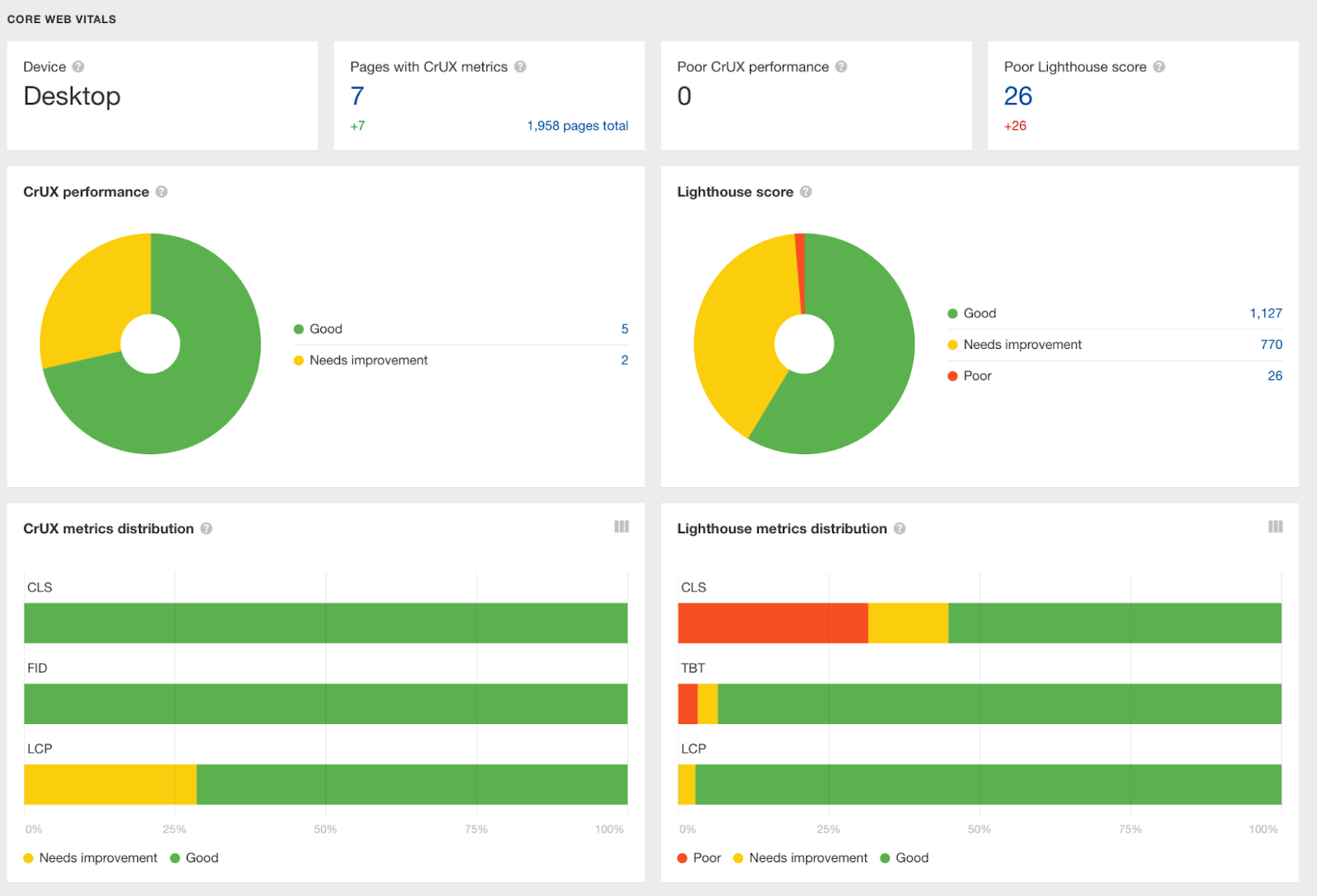
The increasing prevalence of React in modern web development cannot be ignored. React and other similar libraries (like Vue.js) are becoming the de facto choice for larger businesses that require complex development where a more simplistic approach (like using a WordPress theme) won’t satisfy the requirements. Despite that, SEOs did not initially embrace libraries like React due to search engines struggling to effectively render JavaScript, with content available within the HTML source being the preference. However, developments in both how Google and React can render JavaScript have simplified these complexities, resulting in SEO no longer being the blocker for using React. Still, some complexities remain, which I’ll run through in this guide. On that note, here’s what we’ll cover: React is an open-source JavaScript library developed by Meta (formerly Facebook) for building web and mobile applications. The main features of React are that it is declarative, is component-based, and allows easier manipulation of the DOM. The simplest way to understand the components is by thinking of them as plugins, like for WordPress. They allow developers to quickly build a design and add functionality to a page using component libraries like MUI or Tailwind UI. If you want the full lowdown on why developers love React, start here: React implements an App Shell Model, meaning the vast majority of content, if not all, will be Client-side Rendered (CSR) by default. CSR means the HTML primarily contains the React JS library rather than the server sending the entire page’s contents within the initial HTTP response from the server (the HTML source). It will also include miscellaneous JavaScript containing JSON data or links to JS files that contain React components. You can quickly tell a site is client-side rendered by checking the HTML source. To do that, right-click and select “View Page Source” (or CTRL + U/CMD + U). A screenshot of the netlfix.com homepage source HTML. If you don’t see many lines of HTML there, the application is likely client-side rendering. However, when you inspect the element by right-clicking and selecting “Inspect element” (or F12/CMD + ⌥ + I), you’ll see the DOM generated by the browser (where the browser has rendered JavaScript). The result is you’ll then see the site has a lot of HTML: Note the appMountPoint ID on the first <div>. You’ll commonly see an element like that on a single-page application (SPA), so a library like React knows where it should inject HTML. Technology detection tools, e.g., Wappalyzer, are also great at detecting the library. Editor’s Note Ahrefs’ Site Audit saves both the Raw HTML sent from the server and the Rendered HTML in the browser, making it easier to spot whether a site has client-side rendered content. Even better, you can search both the Raw and Rendered HTML to know what content is specifically being rendered client-side. In the below example, you can see this site is client-side rendering key page content, such as the <h1> tag. Websites created using React differ from the more traditional approach of leaving the heavy-lifting of rendering content on the server using languages like PHP—called Server-side Rendering (SSR). The above shows the server rendering JavaScript into HTML with React (more on that shortly). The concept is the same for sites built with PHP (like WordPress). It’s just PHP being turned into HTML rather than JavaScript. Before SSR, developers kept it even simpler. They would create static HTML documents that didn’t change, host them on a server, and then send them immediately. The server didn’t need to render anything, and the browser often had very little to render. SPAs (including those using React) are now coming full circle back to this static approach. They’re now pre-rendering JavaScript into HTML before a browser requests the URL. This approach is called Static Site Generation (SSG), also known as Static Rendering. In practice, SSR and SSG are similar. The key difference is that rendering happens with SSR when a browser requests a URL versus a framework pre-rendering content at build time with SSG (when developers deploy new code or a web admin changes the site’s content). SSR can be more dynamic but slower due to additional latency while the server renders the content before sending it to the user’s browser. SSG is faster, as the content has already been rendered, meaning it can be served to the user immediately (meaning a quicker TTFB). To understand why React’s default client-side rendering approach causes SEO issues, you first need to know how Google crawls, processes, and indexes pages. We can summarize the basics of how this works in the below steps: Historically, issues with React and other JS libraries have been due to Google not handling the rendering step well. Some examples include: Thankfully, Google has now resolved most of these issues. Googlebot is now evergreen, meaning it always supports the latest features of Chromium. In addition, the rendering delay is now five seconds, as announced by Martin Splitt at the Chrome Developer Summit in November 2019: Last year Tom Greenaway and I were on this stage and telling you, ‘Well, you know, it can take up to a week, we are very sorry for this.’ Forget this, okay? Because the new numbers look a lot better. So we actually went over the numbers and found that, it turns out that at median, the time we spent between crawling and actually having rendered these results is – on median – it’s five seconds!” This all sounds positive. But is client-side rendering and leaving Googlebot to render content the right strategy? The answer is most likely still no. In the past five years, Google has innovated its handling of JavaScript content, but entirely client-side rendered sites introduce other issues that you need to consider. It’s important to note that you can overcome all issues with React and SEO. React JS is a development tool. React is no different from any other tool within a development stack, whether that’s a WordPress plugin or the CDN you choose. How you configure it will decide whether it detracts or enhances SEO. Ultimately, React is good for SEO, as it improves user experience. You just need to make sure you consider the following common issues. The most significant issue you’ll need to tackle with React is how it renders content. As mentioned, Google is great at rendering JavaScript nowadays. But unfortunately, that isn’t the case with other search engines. Bing has some support for JavaScript rendering, although its efficiency is unknown. Other search engines like Baidu, Yandex, and others offer limited support. Sidenote. This limitation doesn’t only impact search engines. Apart from site auditors, SEO tools that crawl the web and provide critical data on elements like a site’s backlinks do not render JavaScript. This can have a significant impact on the quality of data they provide. The only exception is Ahrefs, which has been rendering JavaScript across the web since 2017 and currently renders over 200 million pages per day. Introducing this unknown builds a good case for opting for a server-side rendered solution to ensure that all crawlers can see the site’s content. In addition, rendering content on the server has another crucial benefit: load times. Rendering JavaScript is intensive on the CPU; this makes large libraries like React slower to load and become interactive for users. You’ll generally see Core Web Vitals, such as Time to Interactive (TTI), being much higher for SPAs—especially on mobile, the primary way users consume web content. An example React application that utilizes client-side rendering. However, after the initial render by the browser, subsequent load times tend to be quicker due to the following: Depending on the number of pages viewed per visit, this can result in field data being positive overall. However, if your site has a low number of pages viewed per visit, you’ll struggle to get positive field data for all Core Web Vitals. The best option is to opt for SSR or SSG mainly due to: Implementing SSR within React is possible via ReactDOMServer. However, I recommend using a React framework called Next.js and using its SSG and SSR options. You can also implement CSR with Next.js, but the framework nudges users toward SSR/SSG due to speed. Next.js supports what it calls “Automatic Static Optimization.” In practice, this means you can have some pages on a site that use SSR (such as an account page) and other pages using SSG (such as your blog). The result: SSG and fast TTFB for non-dynamic pages, and SSR as a backup rendering strategy for dynamic content. Sidenote. You may have heard about React Hydration with ReactDOM.hydrate(). This is where content is delivered via SSG/SSR and then turns into a client-side rendered application during the initial render. This may be the obvious choice for dynamic applications in the future rather than SSR. However, hydration currently works by loading the entire React library and then attaching event handlers to HTML that will change. React then keeps HTML between the browser and server in sync. Currently, I can’t recommend this approach because it still has negative implications for web vitals like TTI for the initial render. Partial Hydration may resolve this in the future by only hydrating critical parts of the page (like ones within the browser viewport) rather than the entire page; until then, SSR/SSG is the better option. Since we’re talking about speed, I’ll be doing you a disservice by not mentioning other ways Next.js optimizes the critical rendering path for React applications with features like: Speed and positive Core Web Vitals are a ranking factor, albeit a minor one. Next.js features make it easier to create great web experiences that will give you a competitive advantage. TIP Many developers deploy their Next.js web applications using Vercel (the creators of Next.js), which has a global edge network of servers; this results in fast load times. Vercel provides data on the Core Web Vitals of all sites deployed on the platform, but you can also get detailed web vital data for each URL using Ahrefs’ Site Audit. Simply add an API key within the crawl settings of your projects. After you’ve run your audit, have a look at the performance area. There, Ahrefs’ Site Audit will show you charts displaying data from the Chrome User Experience Report (CrUX) and Lighthouse. A common issue with most SPAs is they don’t correctly report status codes. This is as the server isn’t loading the page—the browser is. You’ll commonly see issues with: You can see below I ran a test on a React site with httpstatus.io. This page should obviously be a 404 but, instead, returns a 200 status code. This is called a soft 404. The risk here is that Google may decide to index that page (depending on its content). Google could then serve this to users, or it’ll be used when evaluating a site. In addition, reporting 404s helps SEOs audit a site. If you accidentally internally link to a 404 page and it’s returning a 200 status code, quickly spotting the area with an auditing tool may become much more challenging. There are a couple of ways to solve this issue. If you’re client-side rendering: If you’re using SSR, Next.js makes this simple with response helpers, which let you set whatever status code you want, including 3xx redirects or a 4xx status code. The approach I outlined using React Router can also be put into practice while using Next.js. However, if you’re using Next.js, you’re likely also implementing SSR/SSG. This issue isn’t as common for React, but it’s essential to avoid hash URLs like the following: Generally, Google isn’t going to see anything after the hash. All of these pages will be seen as https://reactspa.com/. SPAs with client-side routing should implement the History API to change pages. You can do this relatively easily with both React Router and Next.js. A common mistake with SPAs is using a <div> or a <button> to change the URL. This isn’t an issue with React itself, but how the library is used. Doing this presents an issue with search engines. As mentioned earlier, when Google processes a URL, it looks for additional URLs to crawl within <a href> elements. If the <a href> element is missing, Google won’t crawl the URLs and pass PageRank. The solution is to include <a href> links to URLs that you want Google to discover. Checking whether you’re linking to a URL correctly is easy. Inspect the element that internally links and check the HTML to ensure you’ve included <a href> links.


1. Pick the right rendering strategy
Load times

Solution
2. Use status codes correctly

3. Avoid hashed URLs
Solution
4. Use <a href> links where relevant
Solution









![6 Major Changes To Content Marketing In 2022 [Report Recap] via @sejournal, @semrush](https://cdn.searchenginejournal.com/wp-content/uploads/2022/03/featured-image-621e8ce87d108-sej.jpg)