The Saga Of John Mueller’s Freaky Robots.txt via @sejournal, @martinibuster
The weird robots.txt file of Google's John Mueller's personal site became an object of curiosity after the site was deindexed The post The Saga Of John Mueller’s Freaky Robots.txt appeared first on Search Engine Journal.
 ValVades
ValVades

The robots.txt file of the personal blog of Google’s John Mueller became a focus of interest when someone on Reddit claimed that Mueller’s blog had been hit by the Helpful Content system and subsequently deindexed. The truth turned out to be less dramatic than that but it was still a little weird.
SEO Subreddit Post
The saga of John Mueller’s robots.txt started when a Redditor posted that John Mueller’s website was deindexed, posting that it fell afoul of Google’s algorithm. But as ironic as that would be that was never going to be the case because all it took was a few seconds to get a load of the website’s robots.txt to see that something strange was going on.
Here’s the top part of Mueller’s robots.txt which features a commented Easter egg for those taking a peek.
The first bit that’s not seen every day is a disallow on the robots.txt. Who uses their robots.txt to tell Google to not crawl their robots.txt?
Now we know.
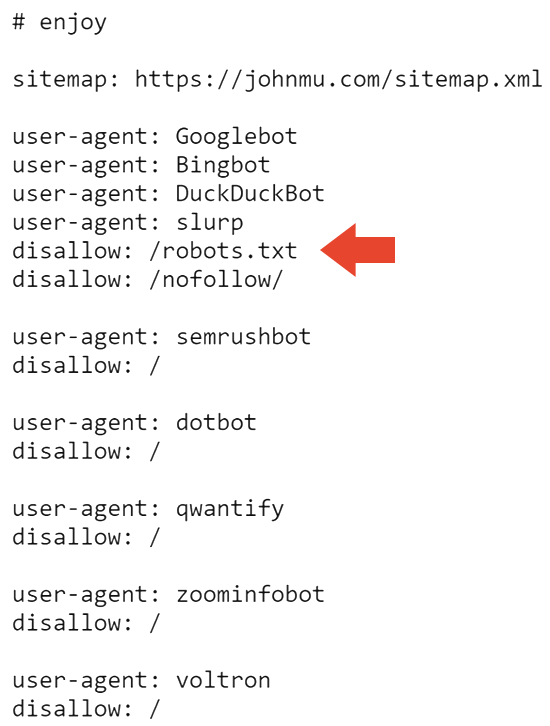
The next part of the robots.txt blocks all search engines from crawling the website and the robots.txt.
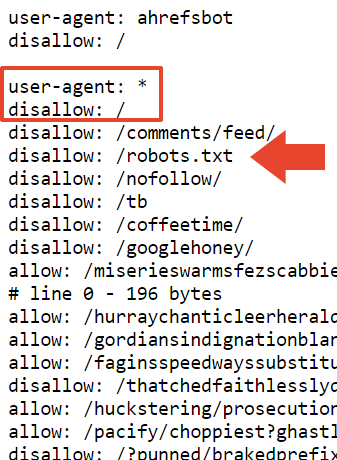
So that probably explains why the site is deindexed in Google. But it doesn’t explain why it’s still indexed by Bing.
I asked around and Adam Humphreys, a web developer and SEO(LinkedIn profile), suggested that it might be that Bingbot hasn’t been around Mueller’s site because it’s a largely inactive website.
Adam messaged me his thoughts:
“User-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file.html
In those examples the folders and that file in that folder wouldn’t be found.
He is saying to disallow the robots file which Bing ignores but Google listens to.
Bing would ignore improperly implemented robots because many don’t know how to do it. “
Adam also suggested that maybe Bing disregarded the robots.txt file altogether.
He explained it to me this way:
“Yes or it chooses to ignore a directive not to read an instructions file.
Improperly implemented robots directions at Bing are likely ignored. This is the most logical answer for them. It’s a directions file.”
The robots.txt was last updated sometime between July and November of 2023 so it could be that Bingbot hasn’t seen the latest robots.txt. That makes sense because Microsoft’s IndexNow web crawling system prioritizes efficient crawling.
One of directories blocked by Mueller’s robots.txt is /nofollow/ (which is a weird name for a folder).
There’s basically nothing on that page except some site navigation and the word, Redirector.
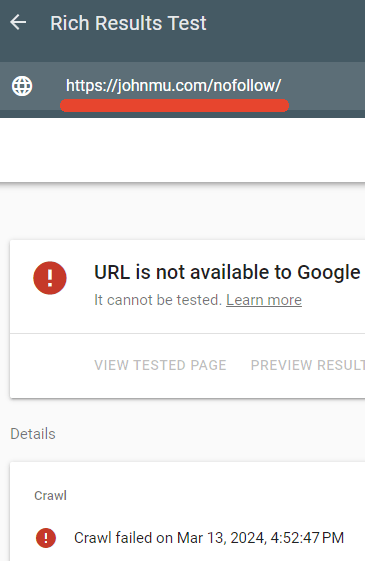
I tested to see if the robots.txt was indeed blocking that page and it was.
Google’s Rich Results tester failed to crawl the /nofollow/ webpage.
John Mueller’s Explanation
Mueller appeared to be amused that so much attention was being paid to his robots.txt and he published an explanation on LinkedIn of what was going on.
He wrote:
“But, what’s up with the file? And why is your site deindexed?
Someone suggested it might be because of the links to Google+. It’s possible. And back to the robots.txt… it’s fine – I mean, it’s how I want it, and crawlers can deal with it. Or, they should be able to, if they follow RFC9309.”
Next he said that the nofollow on the robots.txt was simply to stop it from being indexed as an HTML file.
He explained:
“”disallow: /robots.txt” – does this make robots spin in circles? Does this deindex your site? No.
My robots.txt file just has a lot of stuff in it, and it’s cleaner if it doesn’t get indexed with its content. This purely blocks the robots.txt file from being crawled for indexing purposes.
I could also use the x-robots-tag HTTP header with noindex, but this way I have it in the robots.txt file too.”
Mueller also said this about the file size:
“The size comes from tests of the various robots.txt testing tools that my team & I have worked on. The RFC says a crawler should parse at least 500 kibibytes (bonus likes to the first person who explains what kind of snack that is). You have to stop somewhere, you could make pages that are infinitely long (and I have, and many people have, some even on purpose). In practice what happens is that the system that checks the robots.txt file (the parser) will make a cut somewhere.”
He also said that he added a disallow on top of that section in the hopes that it gets picked up as a “blanket disallow” but I’m not sure what disallow he’s talking about. His robots.txt file has exactly 22,433 disallows in it.
He wrote:
“I added a “disallow: /” on top of that section, so hopefully that gets picked up as a blanket disallow. It’s possible that the parser will cut off in an awkward place, like a line that has “allow: /cheeseisbest” and it stops right at the “/”, which would put the parser at an impasse (and, trivia! the allow rule will override if you have both “allow: /” and “disallow: /”). This seems very unlikely though.”
And there it is. John Mueller’s weird robots.txt.
Robots.txt viewable here: