Using Python + Streamlit To Find Striking Distance Keyword Opportunities via @sejournal, @LeeFootSEO
A Python script can make quick work of your search for lucrative opportunities where your keywords are close to top rankings. Here's how. The post Using Python + Streamlit To Find Striking Distance Keyword Opportunities appeared first on Search...
 Lynk
Lynk

Python is an excellent tool to automate repetitive tasks as well as gain additional insights into data.
In this article, you’ll learn how to build a tool to check which keywords are close to ranking in positions one to three and advises whether there is an opportunity to naturally work those keywords into the page.
It’s perfect for Python beginners and pros alike and is a great introduction to using Python for SEO.
If you’d just like to get stuck in there’s a handy Streamlit app available for the code. This is simple to use and requires no coding experience.
There’s also a Google Colaboratory Sheet if you’d like to poke around with the code. If you can crawl a website, you can use this script!
Here’s an example of what we’ll be making today:
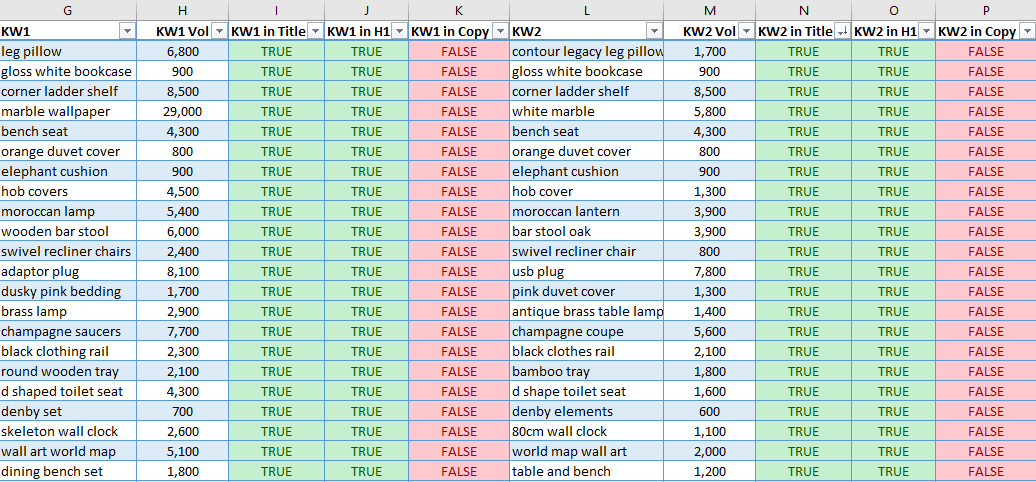 Screenshot from Microsoft Excel, October 2021
Screenshot from Microsoft Excel, October 2021
These keywords are found in the page title and H1, but not in the copy. Adding these keywords naturally to the existing copy would be an easy way to increase relevancy for these keywords.
By taking the hint from search engines and naturally including any missing keywords a site already ranks for, we increase the confidence of search engines to rank those keywords higher in the SERPs.
This report can be created manually, but it’s pretty time-consuming.
So, we’re going to automate the process using a Python SEO script.
Preview Of The Output
This is a sample of what the final output will look like after running the report:
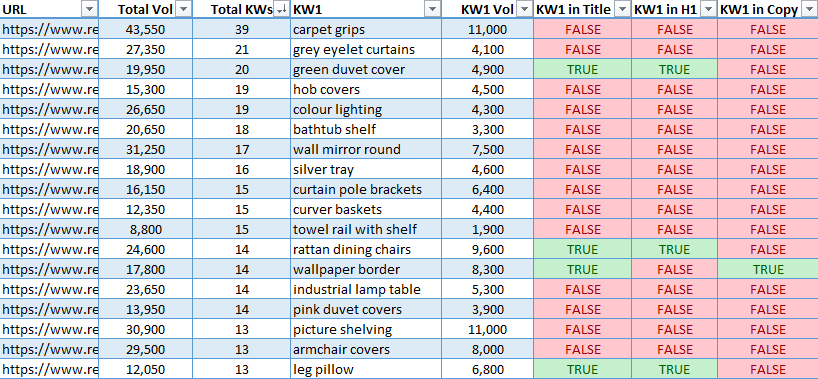 Screenshot from Microsoft Excel, October 2021
Screenshot from Microsoft Excel, October 2021
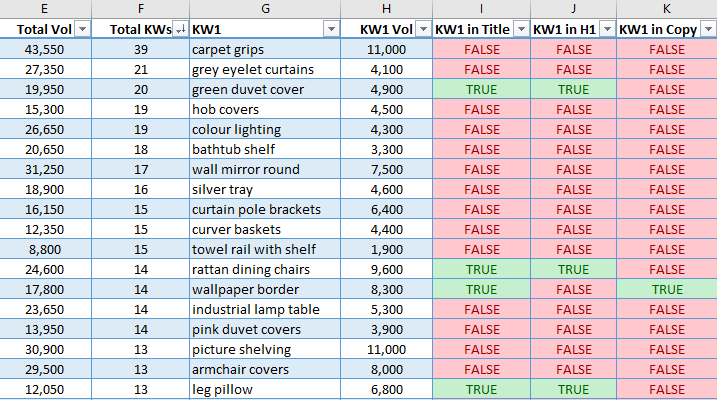
The final output takes the top five opportunities by search volume for each page and neatly lays each one horizontally along with the estimated search volume.
It also shows the total search volume of all keywords a page has within striking distance, as well as the total number of keywords within reach.
The top five keywords by search volume are then checked to see if they are found in the title, H1, or copy, then flagged TRUE or FALSE.
This is great for finding quick wins! Just add the missing keyword naturally into the page copy, title, or H1.
Getting Started
The setup is fairly straightforward. We just need a crawl of the site (ideally with a custom extraction for the copy you’d like to check), and an exported file of all keywords a site ranks for.
This post will walk you through the setup, the code, and will link to a Google Colaboratory sheet if you just want to get stuck in without coding it yourself.
To get started you will need:
A crawl of the website. An export of all keywords a site ranks for. This Google Colab sheet or this Streamlit app to mash up the crawl and keyword dataWe’ve named this the Striking Distance Report as it flags keywords that are easily within striking distance.
(We have defined striking distance as keywords that rank in positions four to 20, but have made this a configurable option in case you would like to define your own parameters.)
Striking Distance SEO Report: Getting Started
1. Crawl The Target Website
Set a custom extractor for the page copy (optional, but recommended). Filter out pagination pages from the crawl.2. Export All Keywords The Site Ranks For Using Your Favorite Provider
Filter keywords that trigger as a site link. Remove keywords that trigger as an image. Filter branded keywords. Use both exports to create an actionable Striking Distance report from the keyword and crawl data with Python.Crawling The Site
I’ve opted to use Screaming Frog to get the initial crawl. Any crawler will work, so long as the CSV export uses the same column names or they’re renamed to match.
The script expects to find the following columns in the crawl CSV export:
"Address", "Title 1", "H1-1", "Copy 1", "Indexability"Crawl Settings
The first thing to do is to head over to the main configuration settings within Screaming Frog:
Configuration > Spider > Crawl
The main settings to use are:
Crawl Internal Links, Canonicals, and the Pagination (Rel Next/Prev) setting.
(The script will work with everything else selected, but the crawl will take longer to complete!)
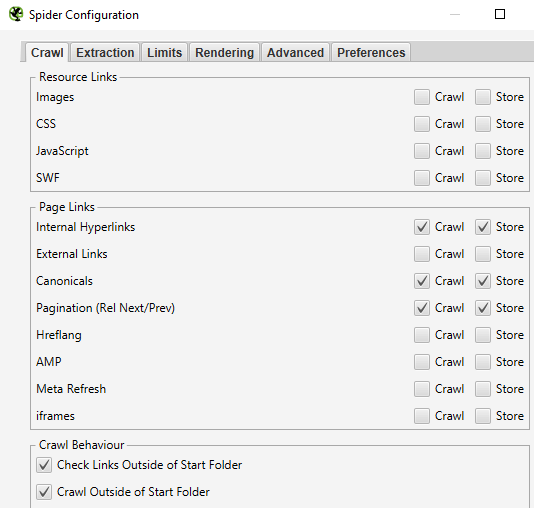 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
Next, it’s on to the Extraction tab.
Configuration > Spider > Extraction
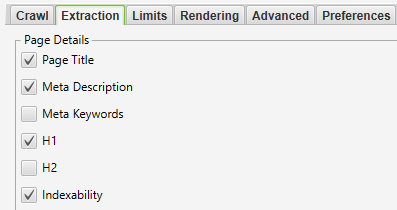 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
At a bare minimum, we need to extract the page title, H1, and calculate whether the page is indexable as shown below.
Indexability is useful because it’s an easy way for the script to identify which URLs to drop in one go, leaving only keywords that are eligible to rank in the SERPs.
If the script cannot find the indexability column, it’ll still work as normal but won’t differentiate between pages that can and cannot rank.
Setting A Custom Extractor For Page Copy
In order to check whether a keyword is found within the page copy, we need to set a custom extractor in Screaming Frog.
Configuration > Custom > Extraction
Name the extractor “Copy” as seen below.
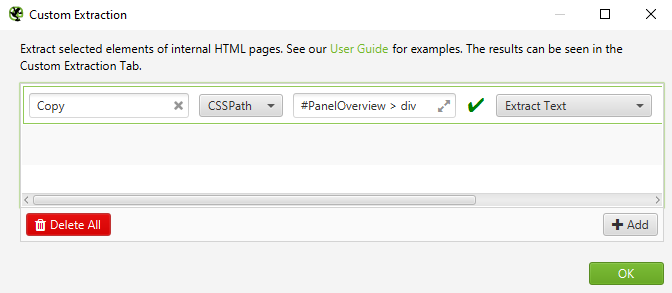 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
Important: The script expects the extractor to be named “Copy” as above, so please double check!
Lastly, make sure Extract Text is selected to export the copy as text, rather than HTML.
There are many guides on using custom extractors online if you need help setting one up, so I won’t go over it again here.
Once the extraction has been set it’s time to crawl the site and export the HTML file in CSV format.
Exporting The CSV File
Exporting the CSV file is as easy as changing the drop-down menu displayed underneath Internal to HTML and pressing the Export button.
Internal > HTML > Export
 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
After clicking Export, It’s important to make sure the type is set to CSV format.
The export screen should look like the below:
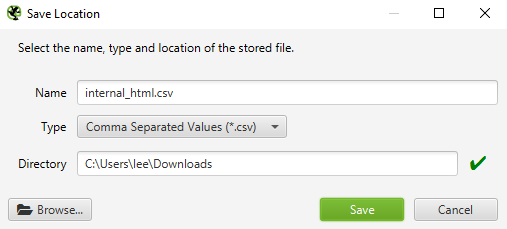 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
Tip 1: Filtering Out Pagination Pages
I recommend filtering out pagination pages from your crawl either by selecting Respect Next/Prev under the Advanced settings (or just deleting them from the CSV file, if you prefer).
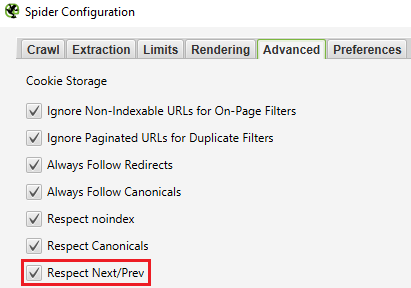 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
Tip 2: Saving The Crawl Settings
Once you have set the crawl up, it’s worth just saving the crawl settings (which will also remember the custom extraction).
This will save a lot of time if you want to use the script again in the future.
File > Configuration > Save As
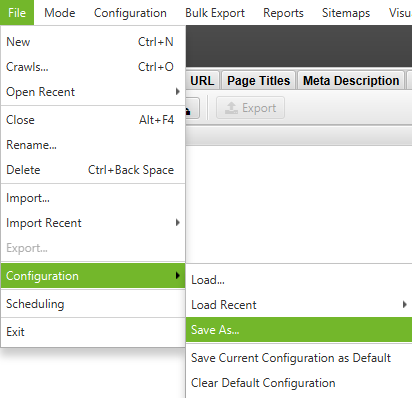 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021
Exporting Keywords
Once we have the crawl file, the next step is to load your favorite keyword research tool and export all of the keywords a site ranks for.
The goal here is to export all the keywords a site ranks for, filtering out branded keywords and any which triggered as a sitelink or image.
For this example, I’m using the Organic Keyword Report in Ahrefs, but it will work just as well with Semrush if that’s your preferred tool.
In Ahrefs, enter the domain you’d like to check in Site Explorer and choose Organic Keywords.
 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021
Site Explorer > Organic Keywords
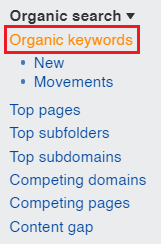 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021
This will bring up all keywords the site is ranking for.
Filtering Out Sitelinks And Image links
The next step is to filter out any keywords triggered as a sitelink or an image pack.
The reason we need to filter out sitelinks is that they have no influence on the parent URL ranking. This is because only the parent page technically ranks for the keyword, not the sitelink URLs displayed under it.
Filtering out sitelinks will ensure that we are optimizing the correct page.
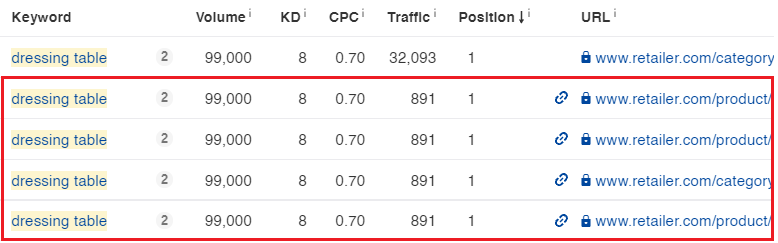 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021
Here’s how to do it in Ahrefs.
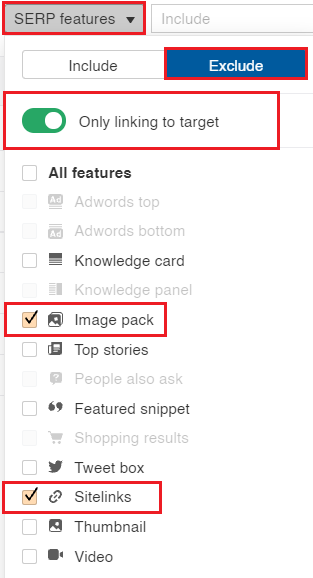 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021
Lastly, I recommend filtering out any branded keywords. You can do this by filtering the CSV output directly, or by pre-filtering in the keyword tool of your choice before the export.
Finally, when exporting make sure to choose Full Export and the UTF-8 format as shown below.
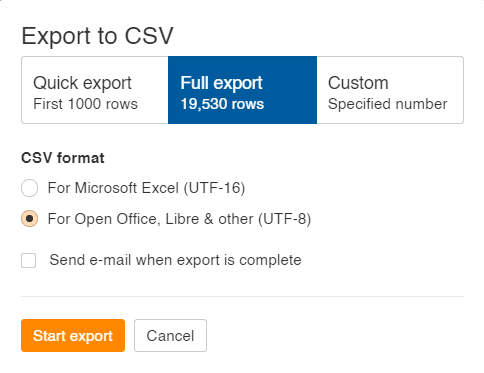 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021
By default, the script works with Ahrefs (v1/v2) and Semrush keyword exports. It can work with any keyword CSV file as long as the column names the script expects are present.
Processing
The following instructions pertain to running a Google Colaboratory sheet to execute the code.
There is now a simpler option for those that prefer it in the form of a Streamlit app. Simply follow the instructions provided to upload your crawl and keyword file.
Now that we have our exported files, all that’s left to be done is to upload them to the Google Colaboratory sheet for processing.
Select Runtime > Run all from the top navigation to run all cells in the sheet.
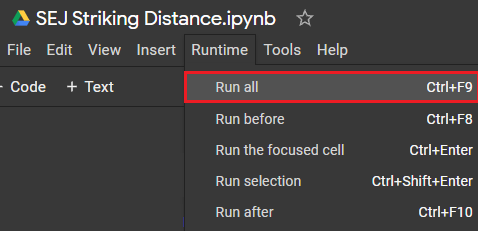 Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
The script will prompt you to upload the keyword CSV from Ahrefs or Semrush first and the crawl file afterward.
![]() Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
That’s it! The script will automatically download an actionable CSV file you can use to optimize your site.
 Screenshot from Microsoft Excel, October 2021
Screenshot from Microsoft Excel, October 2021
Once you’re familiar with the whole process, using the script is really straightforward.
Code Breakdown And Explanation
If you’re learning Python for SEO and interested in what the code is doing to produce the report, stick around for the code walkthrough!
Install The Libraries
Let’s install pandas to get the ball rolling.
!pip install pandasImport The Modules
Next, we need to import the required modules.
import pandas as pd from pandas import DataFrame, Series from typing import Union from google.colab import filesSet The Variables
Now it’s time to set the variables.
The script considers any keywords between positions four and 20 as within striking distance.
Changing the variables here will let you define your own range if desired. It’s worth experimenting with the settings to get the best possible output for your needs.
# set all variables here min_volume = 10 # set the minimum search volume min_position = 4 # set the minimum position / default = 4 max_position = 20 # set the maximum position / default = 20 drop_all_true = True # If all checks (h1/title/copy) are true, remove the recommendation (Nothing to do) pagination_filters = "filterby|page|p=" # filter patterns used to detect and drop paginated pagesUpload The Keyword Export CSV File
The next step is to read in the list of keywords from the CSV file.
It is set up to accept an Ahrefs report (V1 and V2) as well as a Semrush export.
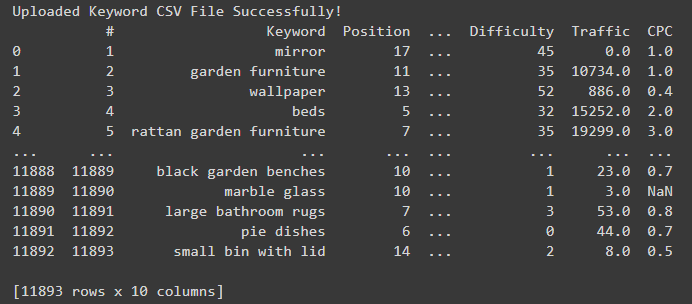
This code reads in the CSV file into a Pandas DataFrame.
upload = files.upload() upload = list(upload.keys())[0] df_keywords = pd.read_csv( (upload), error_bad_lines=False, low_memory=False, encoding="utf8", dtype={ "URL": "str", "Keyword": "str", "Volume": "str", "Position": int, "Current URL": "str", "Search Volume": int, }, ) print("Uploaded Keyword CSV File Successfully!")If everything went to plan, you’ll see a preview of the DataFrame created from the keyword CSV export.
 Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
Upload The Crawl Export CSV File
Once the keywords have been imported, it’s time to upload the crawl file.
This fairly simple piece of code reads in the crawl with some error handling option and creates a Pandas DataFrame named df_crawl. upload = files.upload() upload = list(upload.keys())[0] df_crawl = pd.read_csv( (upload), error_bad_lines=False, low_memory=False, encoding="utf8", dtype="str", ) print("Uploaded Crawl Dataframe Successfully!")Once the CSV file has finished uploading, you’ll see a preview of the DataFrame.
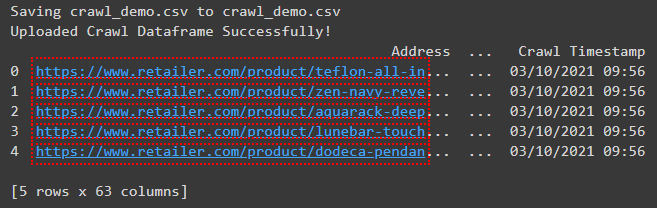 Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
Clean And Standardize The Keyword Data
The next step is to rename the column names to ensure standardization between the most common types of file exports.
Essentially, we’re getting the keyword DataFrame into a good state and filtering using cutoffs defined by the variables.
df_keywords.rename( columns={ "Current position": "Position", "Current URL": "URL", "Search Volume": "Volume", }, inplace=True, ) # keep only the following columns from the keyword dataframe cols = "URL", "Keyword", "Volume", "Position" df_keywords = df_keywords.reindex(columns=cols) try: # clean the data. (v1 of the ahrefs keyword export combines strings and ints in the volume column) df_keywords["Volume"] = df_keywords["Volume"].str.replace("0-10", "0") except AttributeError: pass # clean the keyword data df_keywords = df_keywords[df_keywords["URL"].notna()] # remove any missing values df_keywords = df_keywords[df_keywords["Volume"].notna()] # remove any missing values df_keywords = df_keywords.astype({"Volume": int}) # change data type to int df_keywords = df_keywords.sort_values(by="Volume", ascending=False) # sort by highest vol to keep the top opportunity # make new dataframe to merge search volume back in later df_keyword_vol = df_keywords[["Keyword", "Volume"]] # drop rows if minimum search volume doesn't match specified criteria df_keywords.loc[df_keywords["Volume"] < min_volume, "Volume_Too_Low"] = "drop" df_keywords = df_keywords[~df_keywords["Volume_Too_Low"].isin(["drop"])] # drop rows if minimum search position doesn't match specified criteria df_keywords.loc[df_keywords["Position"] <= min_position, "Position_Too_High"] = "drop" df_keywords = df_keywords[~df_keywords["Position_Too_High"].isin(["drop"])] # drop rows if maximum search position doesn't match specified criteria df_keywords.loc[df_keywords["Position"] >= max_position, "Position_Too_Low"] = "drop" df_keywords = df_keywords[~df_keywords["Position_Too_Low"].isin(["drop"])]Clean And Standardize The Crawl Data
Next, we need to clean and standardize the crawl data.
Essentially, we use reindex to only keep the “Address,” “Indexability,” “Page Title,” “H1-1,” and “Copy 1” columns, discarding the rest.
We use the handy “Indexability” column to only keep rows that are indexable. This will drop canonicalized URLs, redirects, and so on. I recommend enabling this option in the crawl.
Lastly, we standardize the column names so they’re a little nicer to work with.
# keep only the following columns from the crawl dataframe cols = "Address", "Indexability", "Title 1", "H1-1", "Copy 1" df_crawl = df_crawl.reindex(columns=cols) # drop non-indexable rows df_crawl = df_crawl[~df_crawl["Indexability"].isin(["Non-Indexable"])] # standardise the column names df_crawl.rename(columns={"Address": "URL", "Title 1": "Title", "H1-1": "H1", "Copy 1": "Copy"}, inplace=True) df_crawl.head()Group The Keywords
As we approach the final output, it’s necessary to group our keywords together to calculate the total opportunity for each page.
Here, we’re calculating how many keywords are within striking distance for each page, along with the combined search volume.
# groups the URLs (remove the dupes and combines stats) # make a copy of the keywords dataframe for grouping - this ensures stats can be merged back in later from the OG df df_keywords_group = df_keywords.copy() df_keywords_group["KWs in Striking Dist."] = 1 # used to count the number of keywords in striking distance df_keywords_group = ( df_keywords_group.groupby("URL") .agg({"Volume": "sum", "KWs in Striking Dist.": "count"}) .reset_index() ) df_keywords_group.head()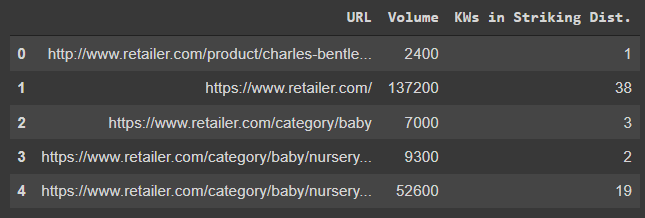 Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
Once complete, you’ll see a preview of the DataFrame.
Display Keywords In Adjacent Rows
We use the grouped data as the basis for the final output. We use Pandas.unstack to reshape the DataFrame to display the keywords in the style of a GrepWords export.
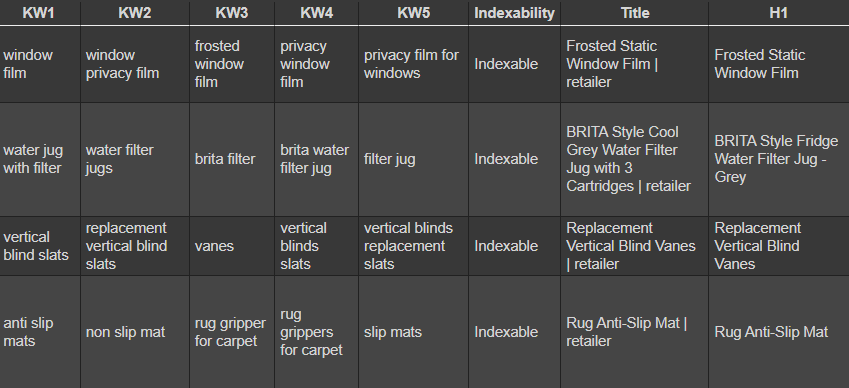 Screenshot from Colab.research.google.com, October 2021
Screenshot from Colab.research.google.com, October 2021
Set The Final Column Order And Insert Placeholder Columns
Lastly, we set the final column order and merge in the original keyword data.
There are a lot of columns to sort and create!
# set the final column order and merge the keyword data in cols = [ "URL", "Title", "H1", "Copy", "Striking Dist. Vol", "KWs in Striking Dist.", "KW1", "KW1 Vol", "KW1 in Title", "KW1 in H1", "KW1 in Copy", "KW2", "KW2 Vol", "KW2 in Title", "KW2 in H1", "KW2 in Copy", "KW3", "KW3 Vol", "KW3 in Title", "KW3 in H1", "KW3 in Copy", "KW4", "KW4 Vol", "KW4 in Title", "KW4 in H1", "KW4 in Copy", "KW5", "KW5 Vol", "KW5 in Title", "KW5 in H1", "KW5 in Copy", ] # re-index the columns to place them in a logical order + inserts new blank columns for kw checks. df_striking = df_striking.reindex(columns=cols)Merge In The Keyword Data For Each Column
This code merges the keyword volume data back into the DataFrame. It’s more or less the equivalent of an Excel VLOOKUP function.
# merge in keyword data for each keyword column (KW1 - KW5) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW1", right_on="Keyword", how="left") df_striking['KW1 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW2", right_on="Keyword", how="left") df_striking['KW2 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW3", right_on="Keyword", how="left") df_striking['KW3 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW4", right_on="Keyword", how="left") df_striking['KW4 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW5", right_on="Keyword", how="left") df_striking['KW5 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True)Clean The Data Some More
The data requires additional cleaning to populate empty values, (NaNs), as empty strings. This improves the readability of the final output by creating blank cells, instead of cells populated with NaN string values.
Next, we convert the columns to lowercase so that they match when checking whether a target keyword is featured in a specific column.
# replace nan values with empty strings df_striking = df_striking.fillna("") # drop the title, h1 and category description to lower case so kws can be matched to them df_striking["Title"] = df_striking["Title"].str.lower() df_striking["H1"] = df_striking["H1"].str.lower() df_striking["Copy"] = df_striking["Copy"].str.lower()Check Whether The Keyword Appears In The Title/H1/Copy and Return True Or False
This code checks if the target keyword is found in the page title/H1 or copy.
It’ll flag true or false depending on whether a keyword was found within the on-page elements.
df_striking["KW1 in Title"] = df_striking.apply(lambda row: row["KW1"] in row["Title"], axis=1) df_striking["KW1 in H1"] = df_striking.apply(lambda row: row["KW1"] in row["H1"], axis=1) df_striking["KW1 in Copy"] = df_striking.apply(lambda row: row["KW1"] in row["Copy"], axis=1) df_striking["KW2 in Title"] = df_striking.apply(lambda row: row["KW2"] in row["Title"], axis=1) df_striking["KW2 in H1"] = df_striking.apply(lambda row: row["KW2"] in row["H1"], axis=1) df_striking["KW2 in Copy"] = df_striking.apply(lambda row: row["KW2"] in row["Copy"], axis=1) df_striking["KW3 in Title"] = df_striking.apply(lambda row: row["KW3"] in row["Title"], axis=1) df_striking["KW3 in H1"] = df_striking.apply(lambda row: row["KW3"] in row["H1"], axis=1) df_striking["KW3 in Copy"] = df_striking.apply(lambda row: row["KW3"] in row["Copy"], axis=1) df_striking["KW4 in Title"] = df_striking.apply(lambda row: row["KW4"] in row["Title"], axis=1) df_striking["KW4 in H1"] = df_striking.apply(lambda row: row["KW4"] in row["H1"], axis=1) df_striking["KW4 in Copy"] = df_striking.apply(lambda row: row["KW4"] in row["Copy"], axis=1) df_striking["KW5 in Title"] = df_striking.apply(lambda row: row["KW5"] in row["Title"], axis=1) df_striking["KW5 in H1"] = df_striking.apply(lambda row: row["KW5"] in row["H1"], axis=1) df_striking["KW5 in Copy"] = df_striking.apply(lambda row: row["KW5"] in row["Copy"], axis=1)Delete True/False Values If There Is No Keyword
This will delete true/false values when there is no keyword adjacent.
# delete true / false values if there is no keyword df_striking.loc[df_striking["KW1"] == "", ["KW1 in Title", "KW1 in H1", "KW1 in Copy"]] = "" df_striking.loc[df_striking["KW2"] == "", ["KW2 in Title", "KW2 in H1", "KW2 in Copy"]] = "" df_striking.loc[df_striking["KW3"] == "", ["KW3 in Title", "KW3 in H1", "KW3 in Copy"]] = "" df_striking.loc[df_striking["KW4"] == "", ["KW4 in Title", "KW4 in H1", "KW4 in Copy"]] = "" df_striking.loc[df_striking["KW5"] == "", ["KW5 in Title", "KW5 in H1", "KW5 in Copy"]] = "" df_striking.head()Drop Rows If All Values == True
This configurable option is really useful for reducing the amount of QA time required for the final output by dropping the keyword opportunity from the final output if it is found in all three columns.
def true_dropper(col1, col2, col3): drop = df_striking.drop( df_striking[ (df_striking[col1] == True) & (df_striking[col2] == True) & (df_striking[col3] == True) ].index ) return drop if drop_all_true == True: df_striking = true_dropper("KW1 in Title", "KW1 in H1", "KW1 in Copy") df_striking = true_dropper("KW2 in Title", "KW2 in H1", "KW2 in Copy") df_striking = true_dropper("KW3 in Title", "KW3 in H1", "KW3 in Copy") df_striking = true_dropper("KW4 in Title", "KW4 in H1", "KW4 in Copy") df_striking = true_dropper("KW5 in Title", "KW5 in H1", "KW5 in Copy")Download The CSV File
The last step is to download the CSV file and start the optimization process.
df_striking.to_csv('Keywords in Striking Distance.csv', index=False) files.download("Keywords in Striking Distance.csv")Conclusion
If you are looking for quick wins for any website, the striking distance report is a really easy way to find them.
Don’t let the number of steps fool you. It’s not as complex as it seems. It’s as simple as uploading a crawl and keyword export to the supplied Google Colab sheet or using the Streamlit app.
The results are definitely worth it!
More Resources:
An Introduction To Python & Machine Learning For Technical SEO How To Do A Sitemap Audit For Better Indexing & Crawling Via Python Advanced Technical SEO: A Complete GuideFeatured Image: aurielaki/Shutterstock