The Modern Guide To Robots.txt: How To Use It Avoiding The Pitfalls via @sejournal, @abbynhamilton
Robots.txt just turned 30! Discover how this simple file still plays a crucial role in controlling how search engines crawl your site. The post The Modern Guide To Robots.txt: How To Use It Avoiding The Pitfalls appeared first on...
 Astrong
Astrong

Robots.txt just turned 30 – cue the existential crisis! Like many hitting the big 3-0, it’s wondering if it’s still relevant in today’s world of AI and advanced search algorithms.
Spoiler alert: It definitely is!
Let’s take a look at how this file still plays a key role in managing how search engines crawl your site, how to leverage it correctly, and common pitfalls to avoid.
What Is A Robots.txt File?
A robots.txt file provides crawlers like Googlebot and Bingbot with guidelines for crawling your site. Like a map or directory at the entrance of a museum, it acts as a set of instructions at the entrance of the website, including details on:
What crawlers are/aren’t allowed to enter? Any restricted areas (pages) that shouldn’t be crawled. Priority pages to crawl – via the XML sitemap declaration.Its primary role is to manage crawler access to certain areas of a website by specifying which parts of the site are “off-limits.” This helps ensure that crawlers focus on the most relevant content rather than wasting the crawl budget on low-value content.
While a robots.txt guides crawlers, it’s important to note that not all bots follow its instructions, especially malicious ones. But for most legitimate search engines, adhering to the robots.txt directives is standard practice.
What Is Included In A Robots.txt File?
Robots.txt files consist of lines of directives for search engine crawlers and other bots.
Valid lines in a robots.txt file consist of a field, a colon, and a value.
Robots.txt files also commonly include blank lines to improve readability and comments to help website owners keep track of directives.
 Image from author, November 2024
Image from author, November 2024
To get a better understanding of what is typically included in a robots.txt file and how different sites leverage it, I looked at robots.txt files for 60 domains with a high share of voice across health, financial services, retail, and high-tech.
Excluding comments and blank lines, the average number of lines across 60 robots.txt files was 152.
Large publishers and aggregators, such as hotels.com, forbes.com, and nytimes.com, typically had longer files, while hospitals like pennmedicine.org and hopkinsmedicine.com typically had shorter files. Retail site’s robots.txt files typically fall close to the average of 152.
All sites analyzed include the fields user-agent and disallow within their robots.txt files, and 77% of sites included a sitemap declaration with the field sitemap.
Fields leveraged less frequently were allow (used by 60% of sites) and crawl-delay (used by 20%) of sites.
| Field | % of Sites Leveraging |
| user-agent | 100% |
| disallow | 100% |
| sitemap | 77% |
| allow | 60% |
| crawl-delay | 20% |
Robots.txt Syntax
Now that we’ve covered what types of fields are typically included in a robots.txt, we can dive deeper into what each one means and how to use it.
For more information on robots.txt syntax and how it is interpreted by Google, check out Google’s robots.txt documentation.
User-Agent
The user-agent field specifies what crawler the directives (disallow, allow) apply to. You can use the user-agent field to create rules that apply to specific bots/crawlers or use a wild card to indicate rules that apply to all crawlers.
For example, the below syntax indicates that any of the following directives only apply to Googlebot.
user-agent: Googlebot
If you want to create rules that apply to all crawlers, you can use a wildcard instead of naming a specific crawler.
user-agent: *
You can include multiple user-agent fields within your robots.txt to provide specific rules for different crawlers or groups of crawlers, for example:
user-agent: *
#Rules here would apply to all crawlers
user-agent: Googlebot
#Rules here would only apply to Googlebot
user-agent: otherbot1
user-agent: otherbot2
user-agent: otherbot3
#Rules here would apply to otherbot1, otherbot2, and otherbot3
Disallow And Allow
The disallow field specifies paths that designated crawlers should not access. The allow field specifies paths that designated crawlers can access.
Because Googlebot and other crawlers will assume they can access any URLs that aren’t specifically disallowed, many sites keep it simple and only specify what paths should not be accessed using the disallow field.
For example, the below syntax would tell all crawlers not to access URLs matching the path /do-not-enter.
user-agent: *
disallow: /do-not-enter
#All crawlers are blocked from crawling pages with the path /do-not-enter
If you’re using both allow and disallow fields within your robots.txt, make sure to read the section on order of precedence for rules in Google’s documentation.
Generally, in the case of conflicting rules, Google will use the more specific rule.
For example, in the below case, Google won’t crawl pages with the path/do-not-enter because the disallow rule is more specific than the allow rule.
user-agent: *
allow: /
disallow: /do-not-enter
If neither rule is more specific, Google will default to using the less restrictive rule.
In the instance below, Google would crawl pages with the path/do-not-enter because the allow rule is less restrictive than the disallow rule.
user-agent: *
allow: /do-not-enter
disallow: /do-not-enter
Note that if there is no path specified for the allow or disallow fields, the rule will be ignored.
user-agent: *
disallow:
This is very different from only including a forward slash (/) as the value for the disallow field, which would match the root domain and any lower-level URL (translation: every page on your site).
If you want your site to show up in search results, make sure you don’t have the following code. It will block all search engines from crawling all pages on your site.
user-agent: *
disallow: /
This might seem obvious, but believe me, I’ve seen it happen.
URL Paths
URL paths are the portion of the URL after the protocol, subdomain, and domain beginning with a forward slash (/). For the example URL https://www.example.com/guides/technical/robots-txt, the path would be /guides/technical/robots-txt.
 Image from author, November 2024
Image from author, November 2024
URL paths are case-sensitive, so be sure to double-check that the use of capitals and lower cases in the robot.txt aligns with the intended URL path.
Special Characters
Google, Bing, and other major search engines also support a limited number of special characters to help match URL paths.
A special character is a symbol that has a unique function or meaning instead of just representing a regular letter or number. Special characters supported by Google in robots.txt are:
Asterisk (*) – matches 0 or more instances of any character. Dollar sign ($) – designates the end of the URL.To illustrate how these special characters work, assume we have a small site with the following URLs:
https://www.example.com/ https://www.example.com/search https://www.example.com/guides https://www.example.com/guides/technical https://www.example.com/guides/technical/robots-txt https://www.example.com/guides/technical/robots-txt.pdf https://www.example.com/guides/technical/xml-sitemaps https://www.example.com/guides/technical/xml-sitemaps.pdf https://www.example.com/guides/content https://www.example.com/guides/content/on-page-optimization https://www.example.com/guides/content/on-page-optimization.pdfExample Scenario 1: Block Site Search Results
A common use of robots.txt is to block internal site search results, as these pages typically aren’t valuable for organic search results.
For this example, assume when users conduct a search on https://www.example.com/search, their query is appended to the URL.
If a user searched “xml sitemap guide,” the new URL for the search results page would be https://www.example.com/search?search-query=xml-sitemap-guide.
When you specify a URL path in the robots.txt, it matches any URLs with that path, not just the exact URL. So, to block both the URLs above, using a wildcard isn’t necessary.
The following rule would match both https://www.example.com/search and https://www.example.com/search?search-query=xml-sitemap-guide.
user-agent: *
disallow: /search
#All crawlers are blocked from crawling pages with the path /search
If a wildcard (*) were added, the results would be the same.
user-agent: *
disallow: /search*
#All crawlers are blocked from crawling pages with the path /search
Example Scenario 2: Block PDF files
In some cases, you may want to use the robots.txt file to block specific types of files.
Imagine the site decided to create PDF versions of each guide to make it easy for users to print. The result is two URLs with exactly the same content, so the site owner may want to block search engines from crawling the PDF versions of each guide.
In this case, using a wildcard (*) would be helpful to match the URLs where the path starts with /guides/ and ends with .pdf, but the characters in between vary.
user-agent: *
disallow: /guides/*.pdf
#All crawlers are blocked from crawling pages with URL paths that contain: /guides/, 0 or more instances of any character, and .pdf
The above directive would prevent search engines from crawling the following URLs:
https://www.example.com/guides/technical/robots-txt.pdf https://www.example.com/guides/technical/xml-sitemaps.pdf https://www.example.com/guides/content/on-page-optimization.pdfExample Scenario 3: Block Category Pages
For the last example, assume the site created category pages for technical and content guides to make it easier for users to browse content in the future.
However, since the site only has three guides published right now, these pages aren’t providing much value to users or search engines.
The site owner may want to temporarily prevent search engines from crawling the category page only (e.g., https://www.example.com/guides/technical), not the guides within the category (e.g., https://www.example.com/guides/technical/robots-txt).
To accomplish this, we can leverage “$” to designate the end of the URL path.
user-agent: *
disallow: /guides/technical$
disallow: /guides/content$
#All crawlers are blocked from crawling pages with URL paths that end with /guides/technical and /guides/content
The above syntax would prevent the following URLs from being crawled:
https://www.example.com/guides/technical https://www.example.com/guides/contentWhile allowing search engines to crawl:
https://www.example.com/guides/technical/robots-txt <https://www.example.com/guides/technical/xml-sitemaps https://www.example.com/guides/content/on-page-optimizationSitemap
The sitemap field is used to provide search engines with a link to one or more XML sitemaps.
While not required, it’s a best practice to include XML sitemaps within the robots.txt file to provide search engines with a list of priority URLs to crawl.
The value of the sitemap field should be an absolute URL (e.g., https://www.example.com/sitemap.xml), not a relative URL (e.g., /sitemap.xml). If you have multiple XML sitemaps, you can include multiple sitemap fields.
Example robots.txt with a single XML sitemap:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.example.com/sitemap.xml
Example robots.txt with multiple XML sitemaps:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.example.com/sitemap-1.xml
sitemap: https://www.example.com/sitemap-2.xml
sitemap: https://www.example.com/sitemap-3.xml
Crawl-Delay
As mentioned above, 20% of sites also include the crawl-delay field within their robots.txt file.
The crawl delay field tells bots how fast they can crawl the site and is typically used to slow down crawling to avoid overloading servers.
The value for crawl-delay is the number of seconds crawlers should wait to request a new page. The below rule would tell the specified crawler to wait five seconds after each request before requesting another URL.
user-agent: FastCrawlingBot
crawl-delay: 5
Google has stated that it does not support the crawl-delay field, and it will be ignored.
Other major search engines like Bing and Yahoo respect crawl-delay directives for their web crawlers.
| Search Engine | Primary user-agent for search | Respects crawl-delay? |
| Googlebot | No | |
| Bing | Bingbot | Yes |
| Yahoo | Slurp | Yes |
| Yandex | YandexBot | Yes |
| Baidu | Baiduspider | No |
Sites most commonly include crawl-delay directives for all user agents (using user-agent: *), search engine crawlers mentioned above that respect crawl-delay, and crawlers for SEO tools like Ahrefbot and SemrushBot.
The number of seconds crawlers were instructed to wait before requesting another URL ranged from one second to 20 seconds, but crawl-delay values of five seconds and 10 seconds were the most common across the 60 sites analyzed.
Testing Robots.txt Files
Any time you’re creating or updating a robots.txt file, make sure to test directives, syntax, and structure before publishing.
This robots.txt Validator and Testing Tool makes this easy to do (thank you, Max Prin!).
To test a live robots.txt file, simply:
Add the URL you want to test. Select your user agent. Choose “live.” Click “test.”The below example shows that Googlebot smartphone is allowed to crawl the tested URL.
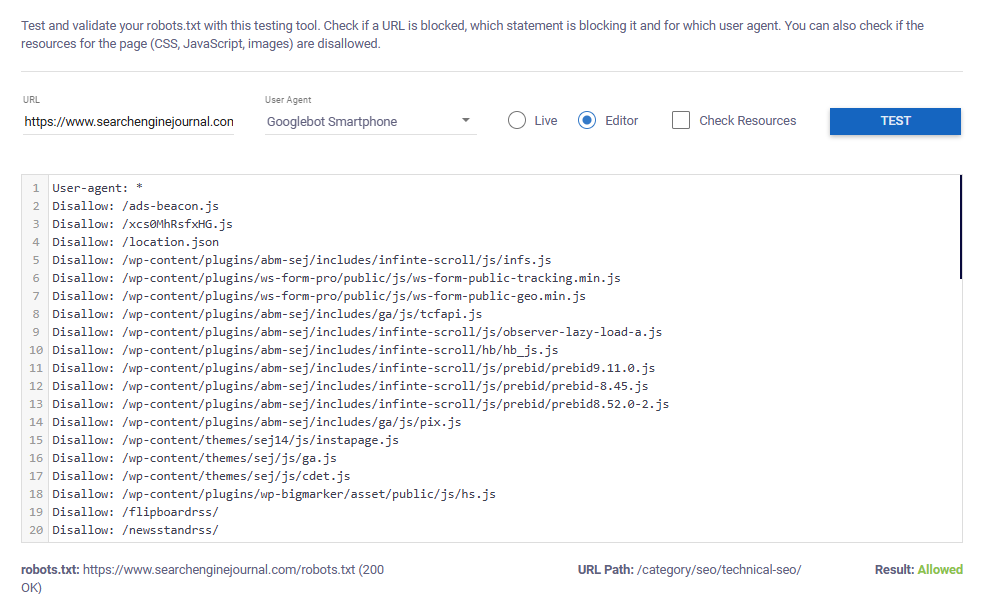 Image from author, November 2024
Image from author, November 2024
If the tested URL is blocked, the tool will highlight the specific rule that prevents the selected user agent from crawling it.
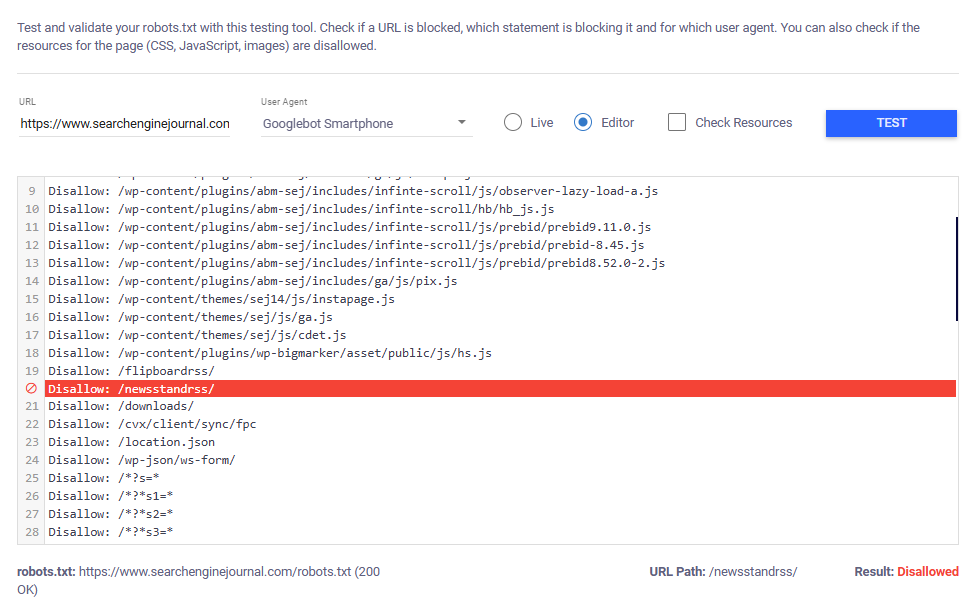 Image from author, November 2024
Image from author, November 2024
To test new rules before they are published, switch to “Editor” and paste your rules into the text box before testing.
Common Uses Of A Robots.txt File
While what is included in a robots.txt file varies greatly by website, analyzing 60 robots.txt files revealed some commonalities in how it is leveraged and what types of content webmasters commonly block search engines from crawling.
Preventing Search Engines From Crawling Low-Value Content
Many websites, especially large ones like ecommerce or content-heavy platforms, often generate “low-value pages” as a byproduct of features designed to improve the user experience.
For example, internal search pages and faceted navigation options (filters and sorts) help users find what they’re looking for quickly and easily.
While these features are essential for usability, they can result in duplicate or low-value URLs that aren’t valuable for search.
The robots.txt is typically leveraged to block these low-value pages from being crawled.
Common types of content blocked via the robots.txt include:
Parameterized URLs: URLs with tracking parameters, session IDs, or other dynamic variables are blocked because they often lead to the same content, which can create duplicate content issues and waste the crawl budget. Blocking these URLs ensures search engines only index the primary, clean URL. Filters and sorts: Blocking filter and sort URLs (e.g., product pages sorted by price or filtered by category) helps avoid indexing multiple versions of the same page. This reduces the risk of duplicate content and keeps search engines focused on the most important version of the page. Internal search results: Internal search result pages are often blocked because they generate content that doesn’t offer unique value. If a user’s search query is injected into the URL, page content, and meta elements, sites might even risk some inappropriate, user-generated content getting crawled and indexed (see the sample screenshot in this post by Matt Tutt). Blocking them prevents this low-quality – and potentially inappropriate – content from appearing in search. User profiles: Profile pages may be blocked to protect privacy, reduce the crawling of low-value pages, or ensure focus on more important content, like product pages or blog posts. Testing, staging, or development environments: Staging, development, or test environments are often blocked to ensure that non-public content is not crawled by search engines. Campaign sub-folders: Landing pages created for paid media campaigns are often blocked when they aren’t relevant to a broader search audience (i.e., a direct mail landing page that prompts users to enter a redemption code). Checkout and confirmation pages: Checkout pages are blocked to prevent users from landing on them directly through search engines, enhancing user experience and protecting sensitive information during the transaction process. User-generated and sponsored content: Sponsored content or user-generated content created via reviews, questions, comments, etc., are often blocked from being crawled by search engines. Media files (images, videos): Media files are sometimes blocked from being crawled to conserve bandwidth and reduce the visibility of proprietary content in search engines. It ensures that only relevant web pages, not standalone files, appear in search results. APIs: APIs are often blocked to prevent them from being crawled or indexed because they are designed for machine-to-machine communication, not for end-user search results. Blocking APIs protects their usage and reduces unnecessary server load from bots trying to access them.Blocking “Bad” Bots
Bad bots are web crawlers that engage in unwanted or malicious activities such as scraping content and, in extreme cases, looking for vulnerabilities to steal sensitive information.
Other bots without any malicious intent may still be considered “bad” if they flood websites with too many requests, overloading servers.
Additionally, webmasters may simply not want certain crawlers accessing their site because they don’t stand to gain anything from it.
For example, you may choose to block Baidu if you don’t serve customers in China and don’t want to risk requests from Baidu impacting your server.
Though some of these “bad” bots may disregard the instructions outlined in a robots.txt file, websites still commonly include rules to disallow them.
Out of the 60 robots.txt files analyzed, 100% disallowed at least one user agent from accessing all content on the site (via the disallow: /).
Blocking AI Crawlers
Across sites analyzed, the most blocked crawler was GPTBot, with 23% of sites blocking GPTBot from crawling any content on the site.
Orginality.ai’s live dashboard that tracks how many of the top 1,000 websites are blocking specific AI web crawlers found similar results, with 27% of the top 1,000 sites blocking GPTBot as of November 2024.
Reasons for blocking AI web crawlers may vary – from concerns over data control and privacy to simply not wanting your data used in AI training models without compensation.
The decision on whether or not to block AI bots via the robots.txt should be evaluated on a case-by-case basis.
If you don’t want your site’s content to be used to train AI but also want to maximize visibility, you’re in luck. OpenAI is transparent on how it uses GPTBot and other web crawlers.
At a minimum, sites should consider allowing OAI-SearchBot, which is used to feature and link to websites in the SearchGPT – ChatGPT’s recently launched real-time search feature.
Blocking OAI-SearchBot is far less common than blocking GPTBot, with only 2.9% of the top 1,000 sites blocking the SearchGPT-focused crawler.
Getting Creative
In addition to being an important tool in controlling how web crawlers access your site, the robots.txt file can also be an opportunity for sites to show their “creative” side.
While sifting through files from over 60 sites, I also came across some delightful surprises, like the playful illustrations hidden in the comments on Marriott and Cloudflare’s robots.txt files.
 Screenshot of marriot.com/robots.txt, November 2024
Screenshot of marriot.com/robots.txt, November 2024
 Screenshot of cloudflare.com/robots.txt, November 2024
Screenshot of cloudflare.com/robots.txt, November 2024
Multiple companies are even turning these files into unique recruitment tools.
TripAdvisor’s robots.txt doubles as a job posting with a clever message included in the comments:
“If you’re sniffing around this file, and you’re not a robot, we’re looking to meet curious folks such as yourself…
Run – don’t crawl – to apply to join TripAdvisor’s elite SEO team[.]”
If you’re looking for a new career opportunity, you might want to consider browsing robots.txt files in addition to LinkedIn.
How To Audit Robots.txt
Auditing your Robots.txt file is an essential part of most technical SEO audits.
Conducting a thorough robots.txt audit ensures that your file is optimized to enhance site visibility without inadvertently restricting important pages.
To audit your Robots.txt file:
Crawl the site using your preferred crawler. (I typically use Screaming Frog, but any web crawler should do the trick.) Filter crawl for any pages flagged as “blocked by robots.txt.” In Screaming Frog, you can find this information by going to the response codes tab and filtering by “blocked by robots.txt.” Review the list of URLs blocked by the robots.txt to determine whether they should be blocked. Refer to the above list of common types of content blocked by robots.txt to help you determine whether the blocked URLs should be accessible to search engines. Open your robots.txt file and conduct additional checks to make sure your robots.txt file follows SEO best practices (and avoids common pitfalls) detailed below.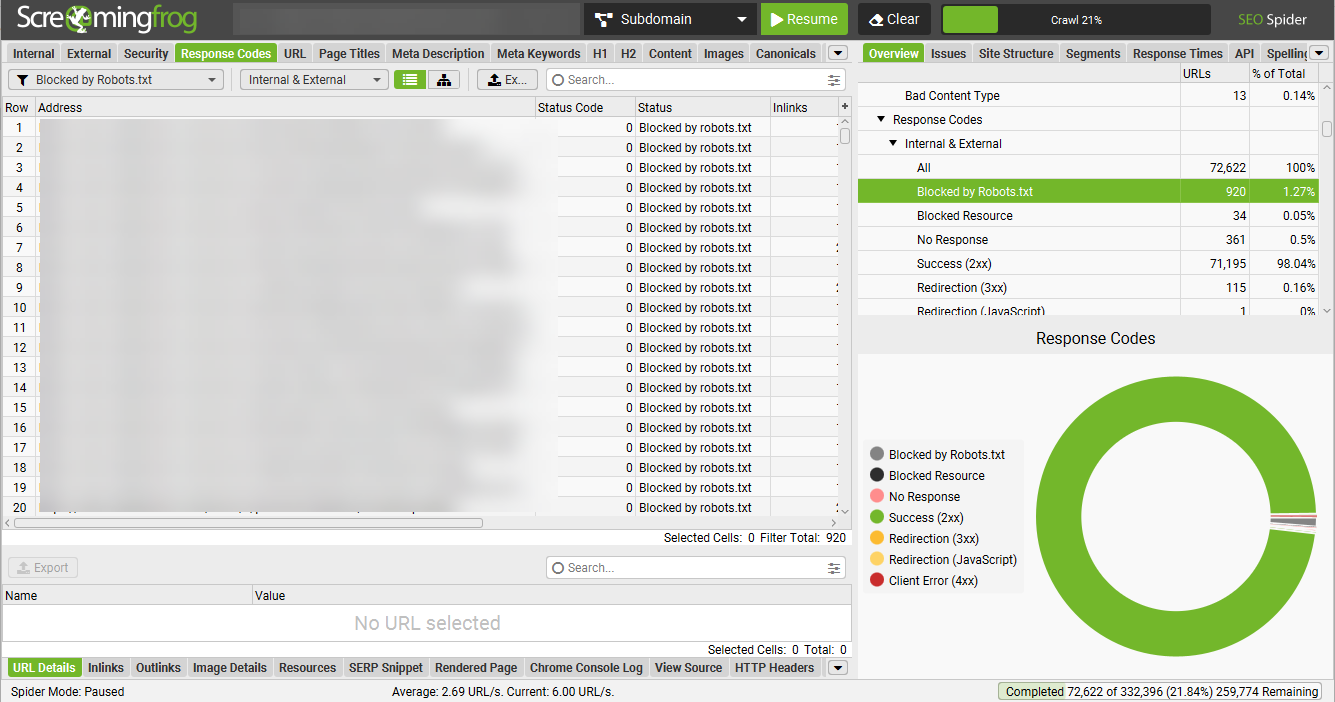 Image from author, November 2024
Image from author, November 2024
Robots.txt Best Practices (And Pitfalls To Avoid)
The robots.txt is a powerful tool when used effectively, but there are some common pitfalls to steer clear of if you don’t want to harm the site unintentionally.
The following best practices will help set yourself up for success and avoid unintentionally blocking search engines from crawling important content:
Create a robots.txt file for each subdomain. Each subdomain on your site (e.g., blog.yoursite.com, shop.yoursite.com) should have its own robots.txt file to manage crawling rules specific to that subdomain. Search engines treat subdomains as separate sites, so a unique file ensures proper control over what content is crawled or indexed. Don’t block important pages on the site. Make sure priority content, such as product and service pages, contact information, and blog content, are accessible to search engines. Additionally, make sure that blocked pages aren’t preventing search engines from accessing links to content you want to be crawled and indexed. Don’t block essential resources. Blocking JavaScript (JS), CSS, or image files can prevent search engines from rendering your site correctly. Ensure that important resources required for a proper display of the site are not disallowed. Include a sitemap reference. Always include a reference to your sitemap in the robots.txt file. This makes it easier for search engines to locate and crawl your important pages more efficiently. Don’t only allow specific bots to access your site. If you disallow all bots from crawling your site, except for specific search engines like Googlebot and Bingbot, you may unintentionally block bots that could benefit your site. Example bots include: FacebookExtenalHit – used to get open graph protocol. GooglebotNews – used for the News tab in Google Search and the Google News app. AdsBot-Google – used to check webpage ad quality. Don’t block URLs that you want removed from the index. Blocking a URL in robots.txt only prevents search engines from crawling it, not from indexing it if the URL is already known. To remove pages from the index, use other methods like the “noindex” tag or URL removal tools, ensuring they’re properly excluded from search results. Don’t block Google and other major search engines from crawling your entire site. Just don’t do it.TL;DR
A robots.txt file guides search engine crawlers on which areas of a website to access or avoid, optimizing crawl efficiency by focusing on high-value pages. Key fields include “User-agent” to specify the target crawler, “Disallow” for restricted areas, and “Sitemap” for priority pages. The file can also include directives like “Allow” and “Crawl-delay.” Websites commonly leverage robots.txt to block internal search results, low-value pages (e.g., filters, sort options), or sensitive areas like checkout pages and APIs. An increasing number of websites are blocking AI crawlers like GPTBot, though this might not be the best strategy for sites looking to gain traffic from additional sources. To maximize site visibility, consider allowing OAI-SearchBot at a minimum. To set your site up for success, ensure each subdomain has its own robots.txt file, test directives before publishing, include an XML sitemap declaration, and avoid accidentally blocking key content.More resources:
8 Common Robots.txt Issues And How To Fix Them 13 Steps To Boost Your Site’s Crawlability And Indexability The Complete Technical SEO Audit WorkbookFeatured Image: Se_vector/Shutterstock












![Semantic Keyword Clustering For 10,000+ Keywords [With Script] via @sejournal, @LeeFootSEO](https://cdn.searchenginejournal.com/wp-content/uploads/2022/02/semantic-keyword-clustering-620b9afcec2c7-sej.png)






















