Before We Use AI to Manage Projects, Let’s Take Data Seriously
Digital agencies are innovators by their very nature, so it’s no wonder that the space is full of excited chatter about how AI is going to transform the industry. But are we running before we can walk with AI? ...
 ValVades
ValVades

Digital agencies are innovators by their very nature, so it’s no wonder that the space is full of excited chatter about how AI is going to transform the industry. But are we running before we can walk with AI?
After all, you wouldn’t jump behind the wheel of a car unless you knew how to drive…even an AI-enabled, autonomous car. Indeed, no car company has yet claimed to make a completely self-driving car: as it stands, there always needs to be a human in the driver’s seat. And that’s because we are still ultimately responsible; using AI does not mean that we are outsourcing agency and judgment. It is only a tool, and we have to make sure that we’re using it well.
But when something looks like an exciting, time-saving solution, sometimes we just want to get on and implement it – without necessarily stopping to consider if we are using it well. And the result is that we don’t get to enjoy its full potential, or even that something could go very wrong.
Fortunately, we can arm ourselves with some basic best practices and knowledge to help get the most out of AI, without suffering the pitfalls.
AI in Agencyland: What Could It Do for Us?
AI is already widely in use for tools that tackle discrete tasks. Possibly you’ve seen one of a number of the AI copywriting programs that have sprung up recently. And though the consensus is that, at present, you still need a human to run a critical eye over the copy that the AI has produced, these apps are becoming more refined every day.
As a case-in-point to demonstrate: an AI actually wrote the title of this article! After being given the text as a prompt, the AI came up with several suggestions for blog titles. While some were a little off, many were perfectly suitable. To all intents and purposes, they sounded like a human writer had created them.
AI copywriters are getting to the point where they sound pretty natural, and that’s partly because there is so much data on which language models can be “trained”. Take a moment to consider the sheer amount of text that exists online: this is all potential language data. Google’s BERT natural language model, for example, is trained on data that includes the entirety of English-language Wikipedia (a whopping 2,500 million words).
But vast amounts of language data is one thing. What if you wanted an AI to understand something more specifically tailored to your organization’s context? Your copywriters and designers might be keen to get a helping hand from AI; can your project and studio managers expect the same?
This is a much bigger ask. As AI needs to be trained on datasets, the data first needs to exist. This means that, in order to train an AI to assist in your project operations, you will need to have a bank of data from previous projects. And, indeed, any agency that has been running for a while will have a significant amount of data about how their projects are run. The trouble is that it might not be usable data.
The worst enemy of any AI developer is bad data. As AI is not a conscious actor, it has no ability to approach and judge information with criticality. Where many (though not all) people get a gut feeling that a piece of information is fake or embellished, AI cannot make this assessment. Humans can go and fact-check something, and thereby course-correct. AI cannot.
This is where the now-classic programming aphorism comes into play: “Garbage in = garbage out”. An AI can’t tell if you are training it on data that is patchy, inconsistent, or full of biases and process errors. It will just take this bad data and learn from it all the same. And the end result will be an AI that replicates these problems.
This is how Amazon accidentally created a hiring AI that discriminated against women, and how the UK government ended up downgrading the exam results of students from lower socio-economic backgrounds. Bad data ended up replicating bias.
These are both extreme cases with terribly unfair consequences. Using AI to augment your project management is unlikely to be fraught with quite the same level of ethical responsibility, but they still illustrate a vital point. If you train an AI on shoddy data, you can end up with something that causes more harm than good. In a project management context, this might look like inaccurate predictions and unhelpful estimations. If you act likewise uncritically on these suggestions, it’s not difficult to imagine the sort of trouble you could end up in.
So, now you know only to train AI on good data, we have to ask the question: what makes good data?
The Only Way is Good Data
As a project-based organization, how confident are you that you are collecting quality data on your projects? What might that even entail? As well as project length and value, and which projects go over time or over budget, you might track at a more granular level. What types of tasks tend to overrun; what skills do these tasks involve? Which skills are continually overutilized, and which are underutilized? At what points during projects do problems tend to arise – is there a pattern?
This is the kind of data that can come together to create a really vivid picture of your project operations. Indeed, if you have this kind of detailed data, a predictive system could use this to give you some project management assistance. Wouldn’t it be handy if you could get a warning in plenty of time before a critical task overran and caused a delay?
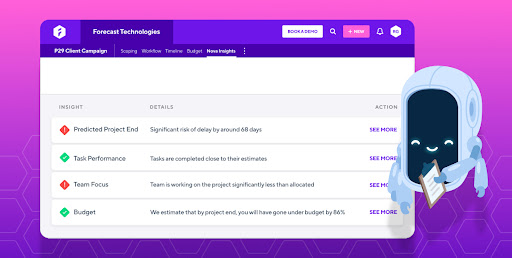 A vision of the future of project management
A vision of the future of project managementWith the way AI is developing, this is not a farfetched vision. But, once again, the reality stands that the AI’s project management suggestions will only ever be reliable and useful if it is trained on good data. And with so many data points to capture, the risk of error is extremely high.
On average, 47% of newly created data records have at least one critical error. People do not intuitively appreciate the value of good data, and most of us are not very good at inputting data manually. Our eyes can skip over fields; colleagues from different countries might enter dates in different formats; we might make typos…the various ways we can make mistakes in data input are as unique and unpredictable as we are!
Data inputting does not really play to our strengths as people. A program that is created to collect and process data will almost invariably do a more consistent job than a person would be able to do. And where this isn’t possible, a well-designed UI that enables consistent data entry patterns can make a big difference.
So, the failsafe way to gather good project data is to manage your projects through a system that is set up for this purpose. A system like Forecast is built with data integrity in mind, specifically for the purpose of machine learning. As much of the data collection as possible is automated, and where this is not possible, the UI encourages simple, consistent entries (for example, of time registrations).
Forecast gives you the ability to get all your project data existing in one ecosystem, which makes it ideal for machine learning purposes. In essence, the Forecast system “learns” how you run your projects over time as you interact with it. And with this quality project data, Forecast is doing big things. Suffice to say that managing complex agency projects is about to get a lot easier.
From Great Data Comes Great AI
It wouldn’t be inaccurate to say that AI is only as smart as we make it. If we want AI to help us with as intricate and complex a task as project management, we need to train it on data that reflects all this complexity in fine, accurate detail. It isn’t an impossibility, but it is a significant challenge.
If we fail to provide AI with this level of data, and expect it to work just as well, we’ll have nobody to blame but ourselves when its predictions are wrong or its suggestions are ludicrous. But rather than being intimidated by this, we should be excited by the possibilities. We are ultimately in control – we just need to take data seriously.









_1.png)