Canonicalization: What It Is & How It Works
According to Google Webmaster Trends Analyst Gary Illyes, ~60% of the internet is duplicate content. Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate
 Tekef
Tekef

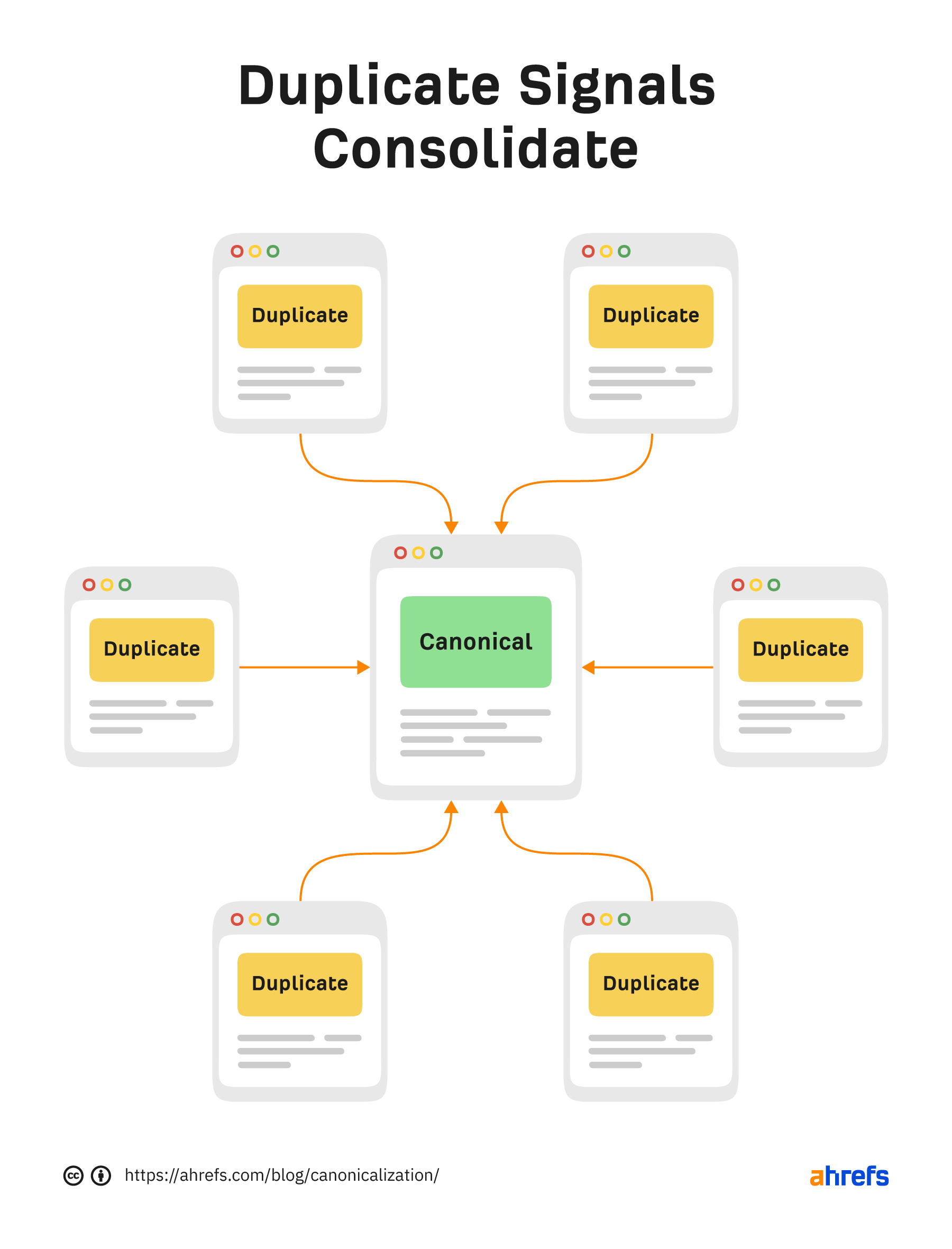
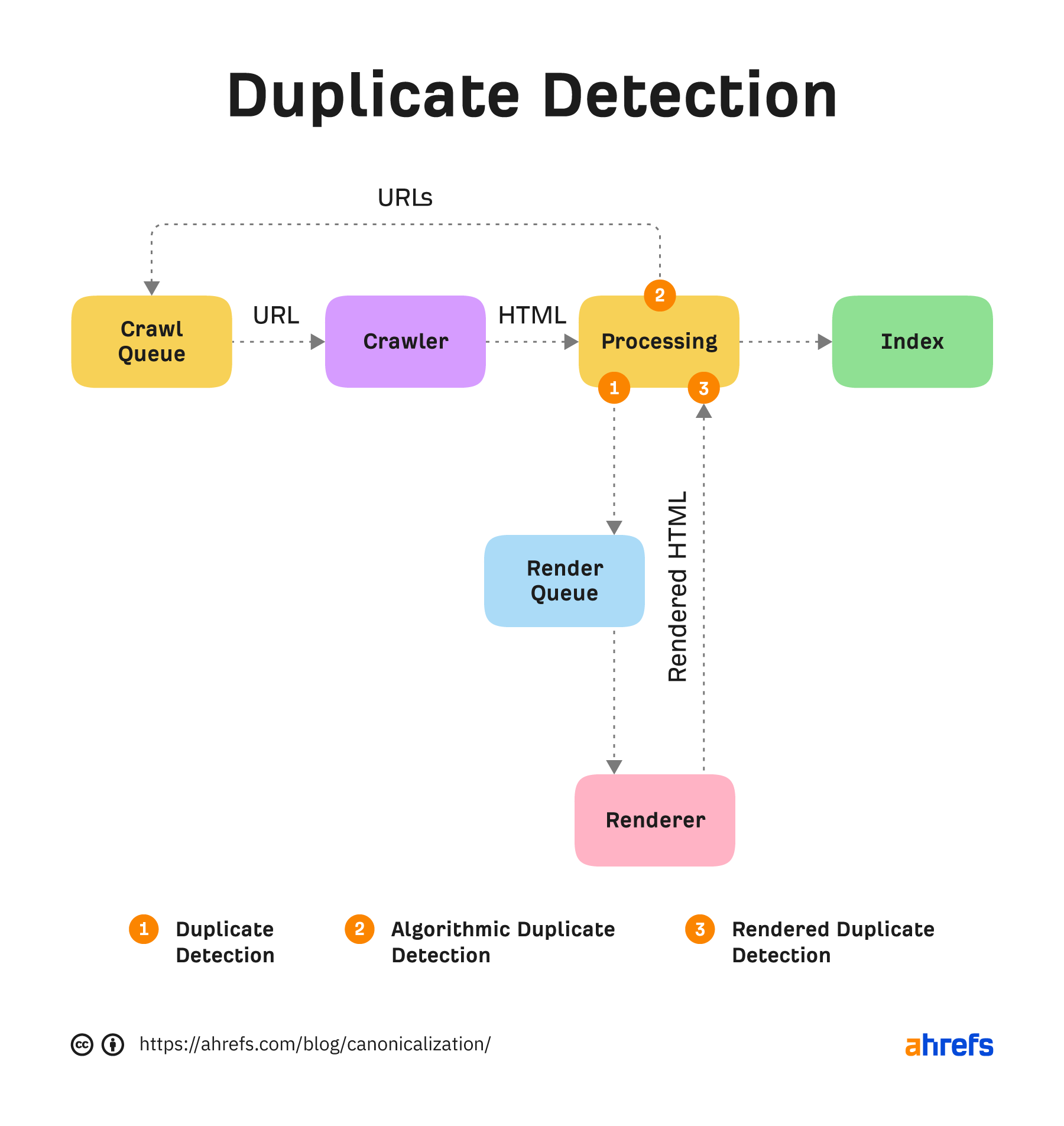
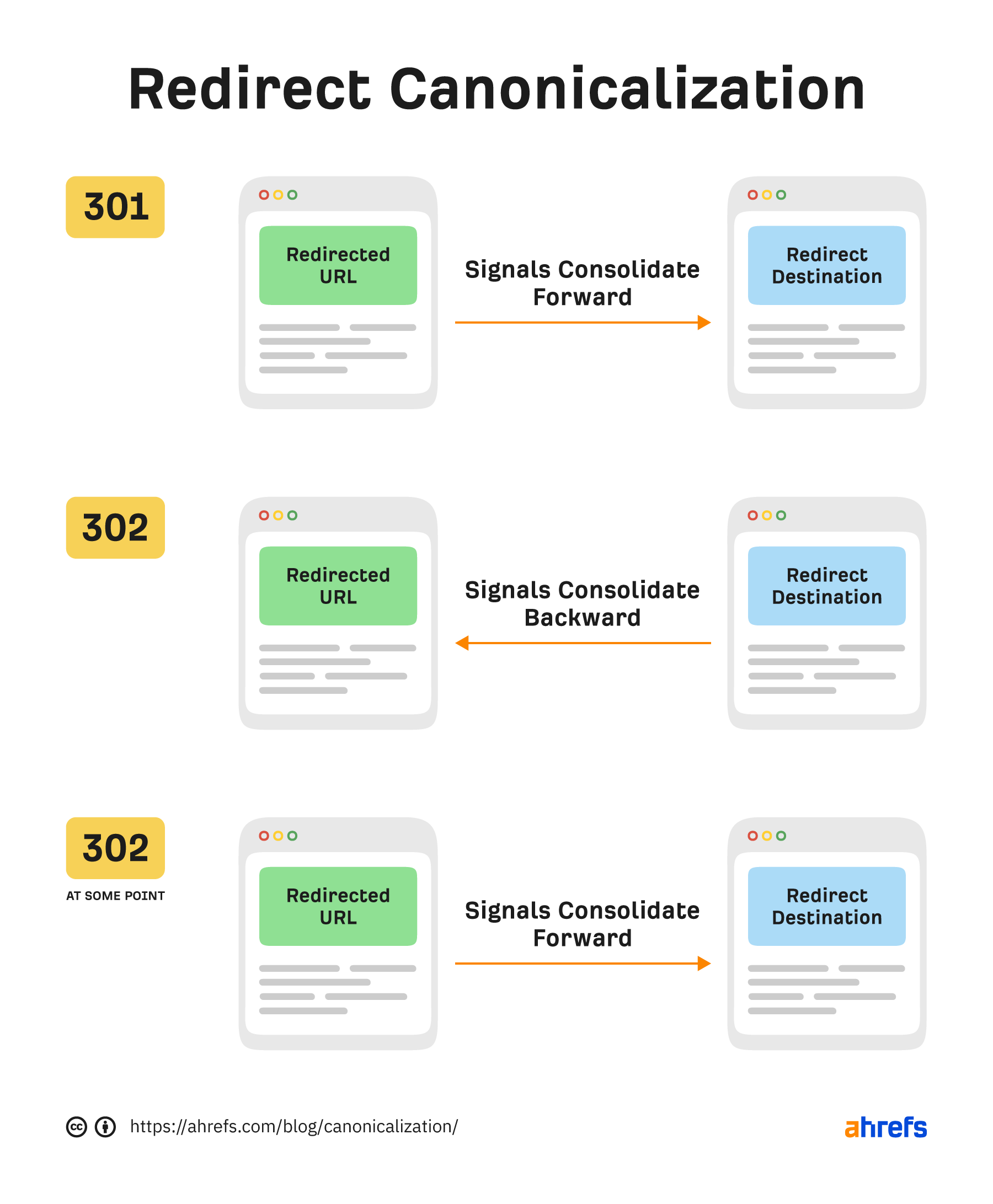
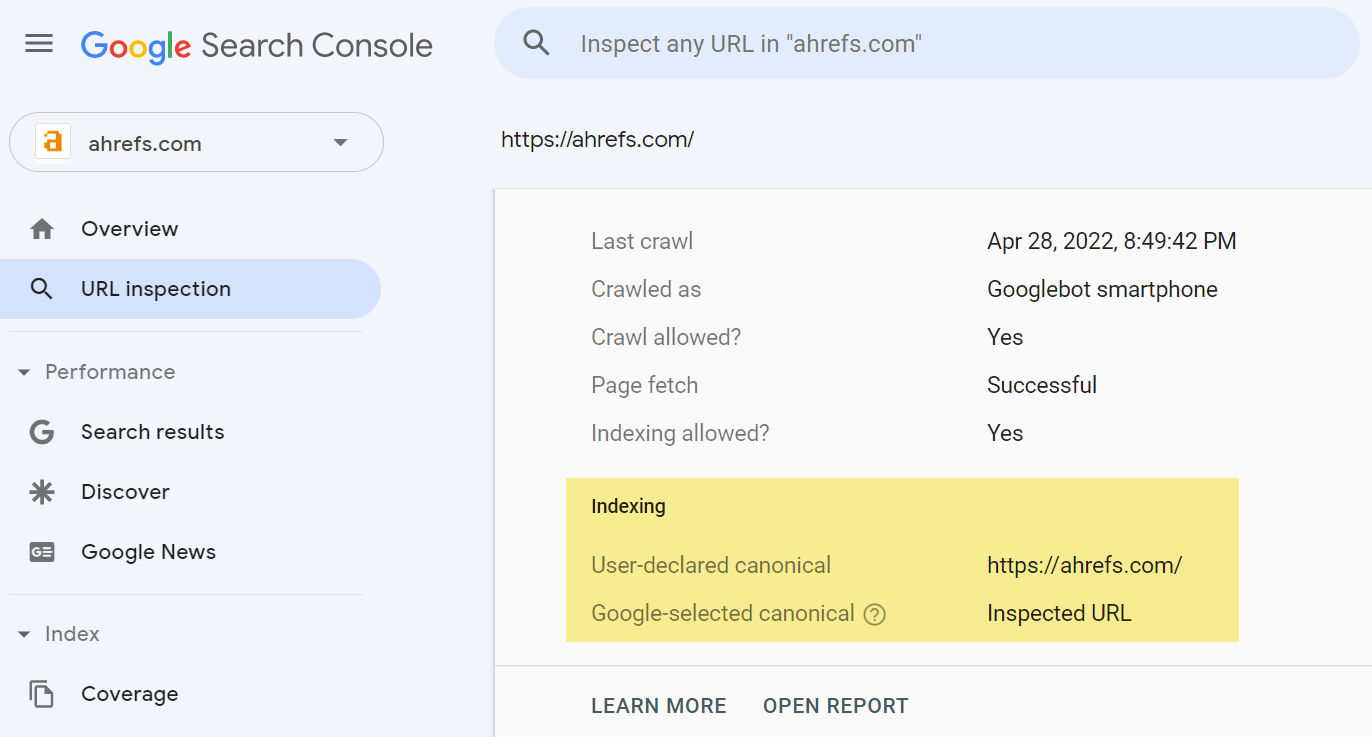
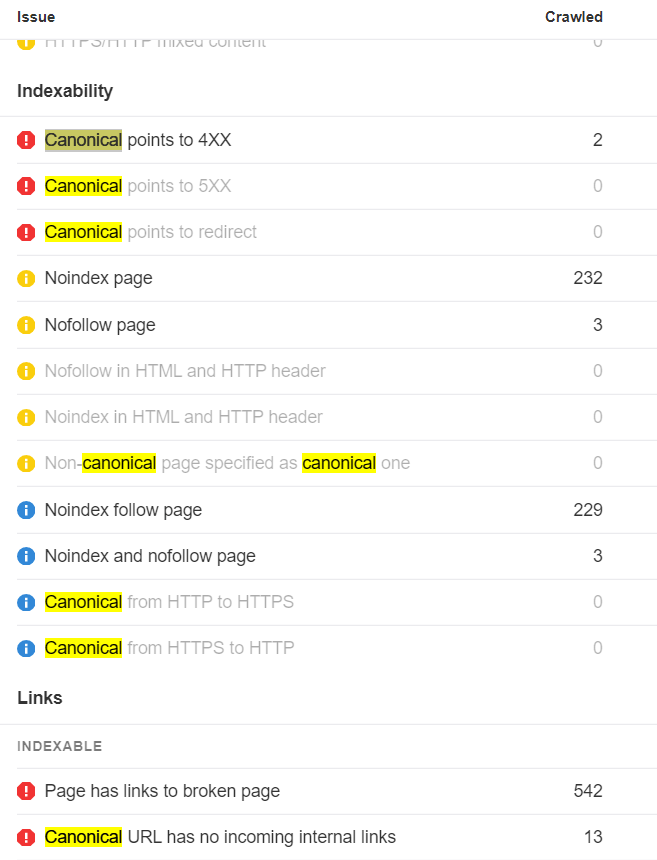
Canonicalization is the process that search engines use to determine the main version of a page. That is the page that will be indexed and shown to users. The chosen version is canonical, and ranking signals like links will consolidate to that page. This process is sometimes referred to as standardization or normalization. According to Google Webmaster Trends Analyst Gary Illyes, ~60% of the internet is duplicate content. Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate 🤯 @methode #seodaydk pic.twitter.com/OJ9OkP74DU Canonicalization is complex and often misunderstood. I don’t think most of the duplicates are nefarious. It’s mostly going to be technical issues that cause them. We’ll look at this more in a bit. I’m going to talk about how the canonicalization process works, as well as the following: A lot of different signals go into the canonicalization process. These include: Google looks at all the different signals and weighs them to determine what the canonical version should be. That’s the version of the page it will index and what it usually shows to users. A potential scenario when Google decides on the canonical based on internal links and the canonical URL. With duplicate content, Google will pick a canonical version to index. All the eligible pages form a cluster of pages, and the signals that go to the pages in that cluster will consolidate at the chosen canonical. That canonical may even change over time. Some SEOs believe there is a duplicate content penalty, but that’s not true. Generally, you’re going to have one version or another indexed. It may not be the version you want to be indexed, but it will be indexed and rank just as well as any other version of the same page. Here are some examples of what can cause duplicate pages and sometimes canonicalization issues: Most of these aren’t usually issues. As I mentioned, Google will usually choose one version or another as the canonical. There are a few exceptions to this. I believe part of the problem with both hreflang and the JavaScript content is that Google may be running the duplicate detection via crawl algorithms that detect duplication patterns, again after just seeing the code and yet again after rendering the pages. Google’s render path marked up where I believe duplicate detection systems are run. With the pages using hreflang, if it decides that the pages are duplicates without crawling them, it may not be able to swap them properly. Before a page is even rendered, it may “look” like another page based on the HTML content. Google may choose the canonical based on this initial version and may not prioritize it for rendering because it’s already deemed a duplicate page. This usually resolves itself after rendering, but it can take some time to clear up. Google has a couple of rules it generally follows when it comes to canonicalization of duplicates. Google will generally index the HTTPS version, but there are a few issues or conflicting signals that may cause it to choose the HTTP version instead, such as: This has been misconstrued over the years by SEOs to say that all your URLs should be shorter. But that’s not what was meant by the original statement. What Google said was that if you had, for instance, a clean, short version of a URL and a longer version with parameters attached, it would generally choose the shorter version of the URL without the parameter as the canonical version. This is also commonly referred to as a canonical tag. It looks like this: <link rel=”canonical” https://www.example.com /> The canonical tag is sometimes referred to as a hint because it’s just one canonicalization signal. Google ignores it if other signals are stronger. If the canonical tag is respected, all signals like links will pass. However, if the canonical is ignored, no value is passed. The value isn’t lost; it stays with the original page or goes to whatever page Google chooses as the canonical. A canonical link element can be implemented in two different ways. It can be in the <head> section or the HTTP header. A fun anecdote. Google’s SEO Starter Guide used to be a PDF. It didn’t have a canonical tag set in the HTTP header, and people used to “steal” the listing with their own duplicate version. Sometimes the <head> section of a page will end before it should. This is usually caused by a tag in the <head> not closed out properly. When that happens, a canonical tag may be put into the <body> section instead. If that happens, your canonical tag won’t be respected. Invalid canonical tag located in the <body> section. The URLs you include in your sitemap are also a canonicalization signal. Most of the time, you only want to include URLs of pages that you want to be indexed. There are some exceptions to this because sitemap URLs also help with crawling. After a website migration, you should create a sitemap that still lists the old pages, even though they aren’t canonical. This will help the redirects be processed faster. You’ll want to delete this sitemap after most of the redirects have been picked up and processed. It matters how you link to pages. Internal links are another canonicalization signal. Generally, you should link to the version of a page you want to be canonical and update the links to any URLs that may have changed. However, there are exceptions to this, such as with faceted navigation. In some cases like this, what is best for users may trump what is best for SEO. There are several different types of redirects, and they’re all canonicalization signals. They pass PageRank and help determine which URL gets shown in Google’s index. 301s and 308s send signals forward to the new URL. 302s and some 307s send signals backward to the redirected URL. If a 302 is left in place long enough or the URL it’s redirected to already exists, it may be treated as a 301 and send signals forward instead. It requires enough signals to flip the scale we saw earlier for canonicalization signals. As links build up, internal links are changed, sitemap URLs are updated, etc., more signals point to the new URL than the old URL, and the flip occurs. At some point, the scale flips for 302s. A 307 has two different cases. In cases where it’s a temporary redirect, it will be treated the same as a 302 and attempt to consolidate backward. When web servers require clients to only use HTTPS connections (HSTS policy), Google won’t see the 307 because it’s cached in the browser. The initial hit (without cache) will have a server response code that’s likely a 301 or a 302. But your browser will show you a 307 for subsequent requests. There are also other types of redirects like those implemented with JavaScript. These are also canonicalization signals and pass the full value just like other redirects as long as they can be seen and processed by Google. They’re fine to use in most cases. Your main source of truth for what Google chose as the canonical will be the URL Inspection tool in Google Search Console. Enter the URL, and it will show what the declared canonical is and what Google chose as the canonical. If you don’t have access to Google Search Console, the recommended way to check the version of a page Google has indexed is to paste the URL into Google. The top result is usually the canonical. Similarly, if you check the cached version of a page in Google and a different page is shown, then Google has selected a different version of the page. Warning: Don’t use site: searches for checking canonicals. It shows what Google knows about, not necessarily what’s indexed or the selected canonical. Within Ahrefs’ Site Audit, we show many issues related to canonicalization. Keep in mind that we’re flagging best practices in most cases. Because the canonical is a hint, Google and other search engines will have to choose which version of a page to index. Even if your website has lots of issues related to canonicalization, search engines may be able to figure out what version should be indexed and where they should consolidate signals. It may not create any real problems for them. Fun fact. When running a site audit, we only count the canonical version of pages as crawl credits. Some other tools count every version of a page toward the credits. On many sites, this can eat multiple credits per page! There’s a lot that can go wrong with canonicalization. Let’s look at some common mistakes. Blocking a URL in robots.txt prevents Google from crawling it, meaning that it cannot see any canonical tags on that page. That, in turn, prevents it from transferring any “link equity” from the non-canonical to the canonical. Unless you have a crawl budget issue, it’s probably better to let all the signals consolidate. Even if you’re going to block or noindex some versions, you may still want to check for versions with links that you should canonicalize instead. However, as Google tends to crawl non-canonical pages less over time, you may just want to wait. Never mix noindex and rel=canonical. They’re contradictory instructions. As John Mueller states, Google will usually prioritize the canonical tag over the “noindex” tag. Setting a 4XX HTTP status code for a canonicalized URL has the same effect as using the “noindex” tag: Google will be unable to see the canonical tag and transfer “link equity” to the canonical version. Paginated pages should not be canonicalized to the first paginated page in the series. Instead, self-referencing canonicals should be used on all paginated pages. Why? As John stated on Reddit, this is improper use of the rel=canonical. The main thing to avoid, since this post is about canonicalization, is to use the rel=canonical on page 2 pointing to page 1. Page 2 isn’t equivalent to page 1, so the rel=canonical like that would be incorrect. We have a guide on pagination for SEO and best practices if you’re interested. This can remove all versions of a URL, effectively deindexing your page from search. As we talked about earlier, there are many different canonicalization signals. Having different signals suggest different canonicals means that you will be relying on Google to select a canonical for you. The more consistent signals you show Google with your preferred version, the more likely it is that version will be the chosen canonical. Hreflang tags specify the language and geographical targeting of a webpage. Google states that when using hreflang, you should “specify a canonical page in the same language, or the best possible substitute language if a canonical doesn’t exist for the same language.” Having multiple rel=canonical tags will usually cause Google to ignore them. In many cases, this happens because tags are inserted into a system at different points, such as by the CMS, the theme, and plugin(s). This is why many plugins have an overwrite option meant to ensure they are the only source for canonical tags. Another area where this may be a problem is with canonicals added with JavaScript. If you have no canonical URL specified in the HTML response and then add a rel=canonical tag with JavaScript, it should be respected when Google renders the page. However, if you have a canonical specified in HTML and swap the preferred version with JavaScript, you send mixed signals to Google. Rel=canonical should only appear in the <head> of a document. A canonical tag in the <body> section of a page will be ignored. Where this can become a problem is with the parsing of a document. Even if the page’s source code has the rel=canonical tag in the correct place, many different things, such as unclosed tags, JavaScript injected, or <iframes> in the <head> section, can cause the <head> to end prematurely while rendering. In these cases, a canonical tag may be accidentally thrown into the <body> of a rendered page where it will not be respected. Many of the tools SEOs had for handling canonicalization have been taken away, such as the URL Parameters Tool and Preferred Domain setting in Google Search Console. However, there are still plenty of other signals to help Google choose a canonical. If you have questions, message me on Twitter.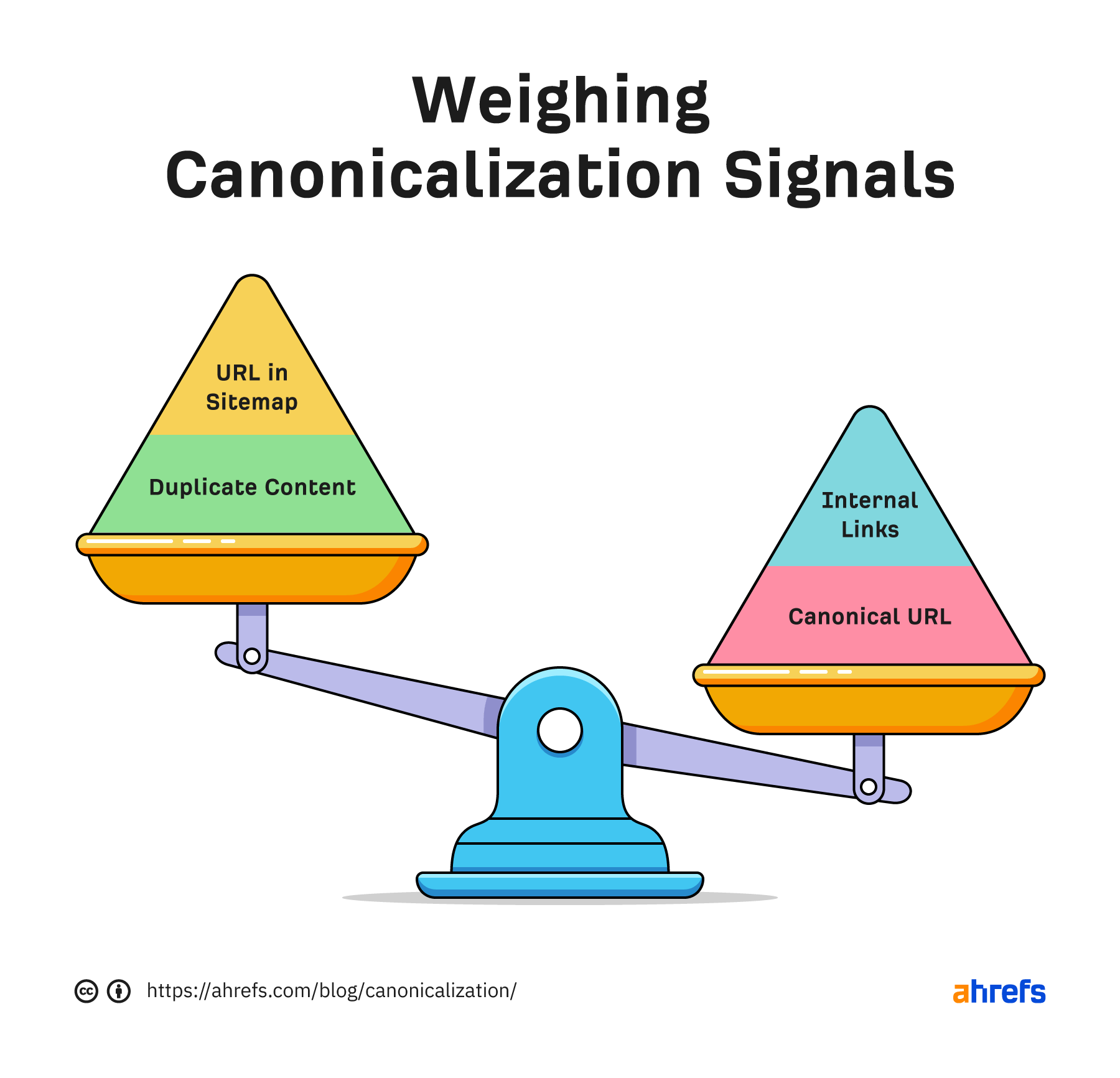
Duplicates
1. It prefers HTTPS pages over HTTP pages.
2. It prefers shorter URLs over longer URLs.
Canonical link element

Sitemap URLs
Internal links
Redirects
Mistake #1. Blocking the canonicalized URL via robots.txt
Mistake #2. Setting the canonicalized URL to “noindex”
Mistake #3. Setting a 4XX HTTP status code for the canonicalized URL
Mistake #4. Canonicalizing all paginated pages to the root page

Mistake #5. Using the URL removal tool in Google Search Console for canonicalization
Mistake #6. Not keeping canonicalization signals consistent
Mistake #7. Not using canonical tags with hreflang
Mistake #8. Having multiple rel=canonical tags
Mistake #9. Rel=canonical in the <body>
Final thoughts













![A Complex Art: Marketing to the Different Funnel Stages [Podcast]](https://cdn.searchenginejournal.com/wp-content/uploads/2021/03/funnel-sej-603d692871529.png)