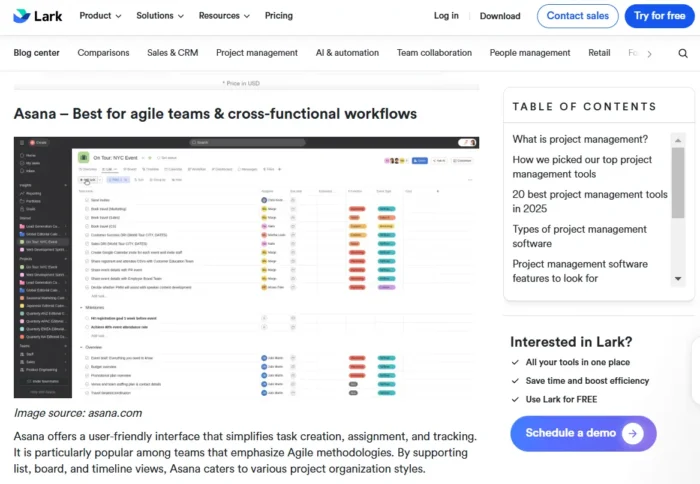
Google On Percentage That Represents Duplicate Content via @sejournal, @martinibuster
Google's John Mueller answers the question of whether there's a percentage at which content is considered duplicate The post Google On Percentage That Represents Duplicate Content appeared first on Search Engine Journal.
 Troov
Troov

Google’s John Mueller recently answered a question of whether there’s a percentage threshold of content duplication that Google uses to identify and filter out duplicate content.
What Percentage Equals Duplicate Content?
The conversation actually started on Facebook when Duane Forrester (@DuaneForrester) asked if anyone knew if any search engine has published a percentage of content overlap at which content is considered duplicate.
Bill Hartzer (bhartzer) turned to Twitter to ask John Mueller and received a near immediate response.
“Hey @johnmu is there a percentage that represents duplicate content?
For example, should we be trying to make sure pages are at least 72.6 percent unique than other pages on our site?
Does Google even measure it?”
Google’s John Mueller responded:
There is no number (also how do you measure it anyway?)
— 🌽〈link href=//johnmu.com rel=canonical 〉🌽 (@JohnMu) September 23, 2022
How Does Google Detect Duplicate Content?
Google’s methodology for detecting duplicate content has remained remarkably similar for many years.
Back in 2013, Matt Cutts (@mattcutts), a software engineer at the time at Google published an official Google video describing how Google detects duplicate content.
He started the video by stating that a great deal of Internet content is duplicate and that it’s a normal thing to happen.
“It’s important ot realize that if you look at content on the web, something like 25% or 30% of all the web’s content is duplicate content.
…People will quote a paragraph of a blog and then link to the blog, that sort of thing.”
He went on to say that because so much of duplicate content is innocent and without spammy intent that Google won’t penalize that content.
Penalizing webpages for having some duplicate content, he said, would have a negative effect on the quality of the search results.
What Google does when it finds duplicate content is:
“…try to group it all together and treat it as if it’s just one piece of content.”
Matt continued:
“It’s just treated as something that we need to cluster appropriately. And we need to make sure that it ranks correctly.”
He explained that Google then chooses which page to show in the search results and that it filters out the duplicate pages in order to improve the user experience.
How Google Handles Duplicate Content – 2020 Version
Fast forward to 2020 and Google published a Search Off the Record podcast episode where the same topic is described in remarkably similar language.
Here is the relevant section of that podcast from the 06:44 minutes into the episode:
“Gary Illyes: And now we ended up with the next step, which is actually canonicalization and dupe detection.
Martin Splitt: Isn’t that the same, dupe detection and canonicalization, kind of?
Gary Illyes: [00:06:56] Well, it’s not, right? Because first you have to detect the dupes, basically cluster them together, saying that all of these pages are dupes of each other,
and then you have to basically find a leader page for all of them.
…And that is canonicalization.
So, you have the duplication, which is the whole term, but within that you have cluster building, like dupe cluster building, and canonicalization. “
Gary next explains in technical terms how exactly they do this. Basically, Google isn’t really looking at percentages exactly, but rather comparing checksums.
A checksum can be said to be a representation of content as a series of numbers or letters. So if the content is duplicate then the checksum number sequence will be similar.
This is how Gary explained it:
“So, for dupe detection what we do is, well, we try to detect dupes.
And how we do that is perhaps how most people at other search engines do it, which is, basically, reducing the content into a hash or checksum and then comparing the checksums.”
Gary said Google does it that way because it’s easier (and obviously accurate).
Google Detects Duplicate Content with Checksums
So when talking about duplicate content it’s probably not a matter of a threshold of percentage, where there’s a number at which content is said to be duplicate.
But rather, duplicate content is detected with a representation of the content in the form of a checksum and then those checksums are compared.
An additional takeaway is that there appears to be a distinction between when part of the content is duplicate and all of the content is duplicate.
Featured image by Shutterstock/Ezume Images













![10 Creative Infographics & Why They Work [With Examples] via @sejournal, @alexanderkesler](https://cdn.searchenginejournal.com/wp-content/uploads/2022/04/image-for-guest-article-SEJ_1600x840_-1.png)