Yandex Data Leak: The Ranking Factors & The Myths We Found via @sejournal, @TaylorDanRW
Learn which ranking factors are prominent in the recent Yandex data leak and what Russian SEO professionals are saying about it. The post Yandex Data Leak: The Ranking Factors & The Myths We Found appeared first on Search Engine...
 Lynk
Lynk

Yandex is the search engine with majority market share in Russia and the fourth largest search engine in the world.
On January 27, 2023, it suffered what is arguably one of the largest data leaks that a modern tech company has endured in many years, but is the second leak in less than a decade.
In 2015, a former Yandex employee attempted to sell Yandex’s search engine code on the black market for around $30,000.
The initial leak in January this year revealed 1,922 ranking factors, of which more than 64% were listed as unused or deprecated (superseded and best avoided).
This leak was just the file labeled kernel, but as the SEO community and I delved deeper, more files were found that combined contain approximately 17,800 ranking factors.
When it comes to practicing SEO for Yandex, the guide I wrote two years ago, for the most part still applies.
Yandex, like Google, has always been public with its algorithm updates and changes, and in recent years how it has adopted machine learning.
Notable updates from the past two-three years include:
Vega (which doubled the size of the index). Mimicry (penalizing fake websites impersonating brands). Y1 update (introducing YATI). Y2 update (late 2022). Adoption of IndexNow. A fresh rollout and assumed update of the PF filter.On a personal note, this data leak is like a second Christmas.
Since January 2020, I’ve run an SEO news website as a hobby dedicated to covering Yandex SEO and search news in Russia with 600+ articles, so this is probably the peak event of the hobby site.
I’ve also spoken twice at the Optimization conference – the largest SEO conference in Russia.
This is also a good test to see how closely Yandex’s public statements match the codebase secrets.
In 2019, working with Yandex’s PR team I was able to interview engineers in their Search team and I asked a number of questions sourced from the wider Western SEO community.
You can read the interview with the Yandex search team here.
Whilst Yandex is primarily known for its presence in Russia, the search engine also has a presence in Turkey, Kazakhstan, and Georgia.
The data leak was believed to be politically motivated and the actions of a rogue employee, and contains a number of code fragments from Yandex’s monolithic repository, Arcadia.
Within the 44GB of leaked data, there’s information relating to a number of Yandex products including Search, Maps, Mail, Metrika, Disc, and Cloud.
What Yandex Has Had To Say
As I write this post (January 31st), Yandex has publicly stated that:
the contents of the archive (leaked code base) correspond to the outdated version of the repository – it differs from the current version used by our services
And:
It is important to note that the published code fragments also contain test algorithms that were used only within Yandex to verify the correct operation of the services.
So how much of this code base is actively used is questionable.
Yandex has also revealed that during their investigation and audit, they found a number of errors that violate their own internal principles, so it is likely that portions of this leaked code (that are in current use) may be changing in the near future.
Factor Classification
Yandex classifies its ranking factors into three categories.
This has been outlined in Yandex’s public documentation for some time, but I feel is worth including here as it better helps us understand the ranking factor leak.
Static factors – Factors that are related directly to the website, e.g. inbound backlinks, inbound internal links, headers, ads ratio. Dynamic factors – Factors that are related to both the website and the search query, e.g. text relevance, keyword inclusions, TF*IDF. User search related factors – Factors relating to the user query, e.g. where is the user located, query language, intent modifiers.The ranking factors in the document are tagged to match the corresponding category, with TG_STATIC and TG_DYNAMIC, and then TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH, and TG_USER_SEARCH_ONLY.
Yandex Leak Learnings So Far
From the data thus far, below are some of the affirmations and learnings we’ve been able to make.
There is so much data in this leak, it is very likely that we will be finding new things and making new connections in the next few weeks.
These include:
PageRank (a form of). At some point Yandex utilized TF*IDF. Yandex still uses meta keywords, which is also highlighted in their documentation. Yandex has specific factors for medical, legal, and financial topics (YMYL). They use a form of page quality scoring, but this is known (ICS score). Links from high authority websites have an impact on rankings. There’s nothing new to suggest Yandex can crawl JavaScript yet outside of already publicly documented processes. Server errors and excessive 4xx errors can impact ranking. The time of day is taken into consideration as a ranking factor.Below, I’ve expanded on some other affirmations and learnings from the leak.
Where possible, I’ve also tied these leaked ranking factors to the algorithm updates and announcements that relate to them, or where we were told about them being impactful.
MatrixNet
MatrixNet is mentioned in a few of the ranking factors and was announced in 2009, and then superseded in 2017 by Catboost, which was rolled out across the Yandex product-sphere.
This further adds validity to comments directly from Yandex, and one of the factor authors DenPlusPlus (Den Raskovalov) that this is in fact an outdated code repository.
Originally introduced as a new, core algorithm that took into consideration thousands of ranking factors and assigned weights based on the user location, the actual search query, and perceived search intent.
MatrixNet is typically seen as a mirror of Google’s RankBrain, or vice versa given MatrixNet was launched 6 years before RankBrain was announced.
MatrixNet has also been built upon, which isn’t surprising given it is now 14 years old.
In 2016, Yandex introduced the Palekh algorithm that used deep neural networks to better match documents (webpages) and queries, even if they didn’t contain the right “levels” of common keywords but satisfied the user intents.
Palekh was capable of processing 150 pages at a time, and in 2017 was updated with the Korolyov update, which took into account more depth of page content, and could work off 200,000 pages at once.
URL & Page Level Factors
From the leak, we have learned that Yandex takes into consideration URL construction, specifically:
The presence of numbers in the URL. The number of trailing slashes in the URL (and if they are excessive). The number of capital letters in the URL is a factor.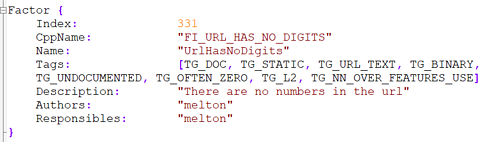 Screenshot from author, January 2023
Screenshot from author, January 2023
The age of a page (document age) and the last updated date are also important, and this makes sense.
As well as document age and last update, a number of factors in the data relate to freshness – particularly for news-related queries.
Yandex formerly used timestamps, specifically not for ranking purposes but “reordering” purposes, but this is now classified as unused.
Also in the deprecated column are the use of keywords in the URL. Yandex has previously measured that three keywords from the search query in the URL would be an “optimal” result.
Internal Links & Crawl Depth
Whilst Google has gone on the record to say that for them, crawl depth isn’t explicitly a ranking factor, Yandex appears to have an active piece of code that dictates that URLs that are reachable from the homepage have a “higher” level of importance.
 Screenshot from author, January 2023
Screenshot from author, January 2023
This mirrors John Mueller’s 2018 statement that Google gives “a little more weight” to pages found more than one click from the homepage.
The ranking factors also highlight a specific token weighting for webpages that are “orphans” within the website linking structure.
Clicks & CTR
In 2011, Yandex released a blog post talking about how the search engine uses clicks as part of their rankings and also addresses the desires of the SEO pros to manipulate the metric for ranking gain.
Specific click factors in the leak look at things like:
The ratio of the number of clicks on the URL, relative to all clicks on the search. The same as above, but broken down by region. How often do users click on the URL for the search.Manipulating Clicks
Manipulating user behavior, specifically “click-jacking” is a known tactic within Yandex.
Yandex has a filter, known as the PF filter that actively seeks out and penalizes websites that engage in this activity using scripts that monitor IP similarities and then the “user actions” of those clicks, and the impact can be significant.
The below screenshot shows the impact on organic sessions (сессии) after being penalized for imitating user clicks.
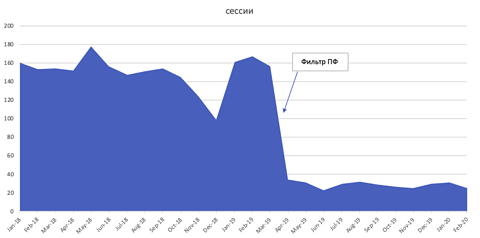 Image from Russian Search News, January 2023
Image from Russian Search News, January 2023
User Behavior
The user behavior takeaways from the leak are some of the more interesting findings.
User behavior manipulation is a common black hat SEO tactic that Yandex has been combatting for years. At the 2020 Optimization conference, then Head of Yandex Webmaster Tools Mikhail Slevinsky said they (Yandex) are making good progress in detecting and penalizing this type of behavior.
Yandex penalizes user behavior manipulation with the same PF filter used to combat CTR manipulation.
Dwell Time
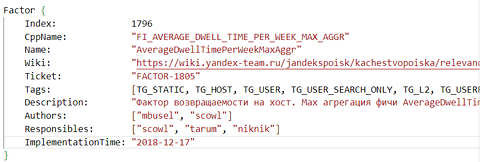
102 of the ranking factors contain the tag TG_USERFEAT_SEARCH_DWELL_TIME, and reference the device, user duration and average page dwell time.
All but 39 of these factors are deprecated.
 Screenshot from author, January 2023
Screenshot from author, January 2023
Bing first used the term Dwell time in a 2011 blog, and in recent years Google have made it clear that they don’t use dwell time (or similar user interaction signals) as ranking factors.
YMYL
YMYL (Your Money, Your Life) is a concept well-known within Google and is not a new concept to Yandex.
Within the data leak, there are specific ranking factors for medical, legal, and financial content that exist – but this was notably revealed in 2019 at the Yandex Webmaster conference when they announced the Proxima Search Quality Metric.
Metrika Data Usage
Six of the ranking factors relate to the usage of Metrika data for the purposes of ranking. However, one of them is tagged as deprecated:
The number of similar visitors from the YandexBar (YaBar/Ябар). The average time spent on URLs from those same similar visitors. The “core audience” of pages on which there is a Metrika counter [deprecated]. The average time a user spends on a host when accessed externally (from another non-search site) from a specific URL. Average ‘depth’ (number of hits within the host) of a user’s stay on the host when accessed externally (from another non-search site) from a particular URL. Whether or not the domain has Metrika installed.In Metrika, user data is handled differently.
Unlike Google Analytics, there are a number of reports focused on user “loyalty” combining site engagement metrics with return frequency, duration between visits, and source of the visit.
For example, I can see a report in one click to see a breakdown of individual site visitors:
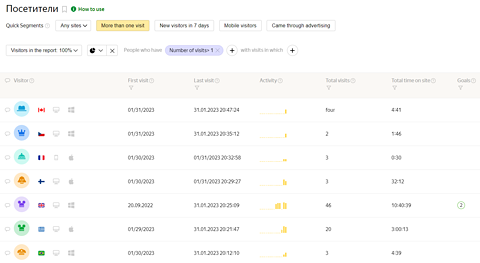 Screenshot from Metrika, January 2023
Screenshot from Metrika, January 2023
Metrika also comes “out of the box” with heatmap tools and user session recording, and in recent years the Metrika team has made good progress in being able to identify and filter bot traffic.
With Google Analytics there is an argument that Google doesn’t use UA/GA4 data for ranking purposes because of how easy it is to modify or break the tracking code, but with Metrika counters they are a lot more linear and a lot of the reports are unchangeable in terms of how the data is collected.
Impact Of Traffic On Rankings
Following on from looking at Metrika data as a ranking factor; these factors effectively confirm that direct traffic and paid traffic (buying ads via Yandex Direct) can impact organic search performance:
Share of direct visits among all incoming traffic. Green traffic share (aka direct visits). Desktop. Green traffic share (aka direct visits). Mobile. Search traffic – transitions from search engines to the site. Share of visits to the site not by links (set by hand or from bookmarks). The number of unique visitors. Share of traffic from search engines.News Factors
There are a number of factors relating to “News”, including two that mention Yandex.News directly.
Yandex.News was an equivalent of Google News but was sold to the Russian social network VKontakte in August 2022, along with another Yandex product “Zen”, so it’s not clear if these factors related to a product no longer owned or operated by Yandex, or to how news websites are ranked in “regular” search.
Backlink Importance
Yandex has similar algorithms to combat link manipulation as Google, and has done since the Nepot filter in 2005.
From reviewing the backlink ranking factors and some of the specifics in the descriptions, we can assume that the best practices for building links for Yandex SEO would be to:
Build links with a more natural frequency and varying amounts. Build links with branded anchor texts as well as use commercial keywords. If buying links, avoid buying links from websites that have mixed topics.Below is a list of link-related factors that can be considered affirmations of best practices:
The age of the backlink is a factor. Link relevance based on topics. Backlinks built from homepages carry more weight than internal pages. Links from the top 100 websites by PR (PageRank) can impact rankings. Link relevance based on the quality of each link. Link relevance, taking into account the quality of each link and the topic of each link. Link relevance, taking into account the non-commercial nature of each link. Percentage of inbound links with query words. Percentage of query words in links (up to a synonym). The links contain all the words of the query (up to a synonym). Dispersion of the number of query words in links.However, there are some link-related factors that are additional considerations when planning, monitoring, and analyzing backlinks:
The ratio of “good” versus “bad” backlinks to a website. The frequency of links to the site. Number of incoming SEO trash links between hosts.The data leak also revealed that the link spam calculator has around 80 active factors that are taken into consideration, with a number of deprecated factors.
This creates the question as to how well Yandex is able to recognize negative SEO attacks, given it looks at the ratio of good versus bad links, and how it determines what a bad link is.
A negative SEO attack is also likely to be a short burst (high frequency) link event in which a site will unwittingly gain a high number of poor quality, non-topical, and potentially over-optimized links.
Yandex uses machine learning models to identify Private Blog Networks (PBNs) and paid links, and they make the same assumption between link velocity and the time period they are acquired.
Typically paid-for links are generated over a longer period of time, and these patterns (including link origin site analysis) are what the Minusinsk update (2015) was introduced to combat.
Yandex Penalties
There are two ranking factors, both deprecated, named SpamKarma and Pessimization.
Pessimization refers to reducing PageRank to zero and aligns with the expectations of severe Yandex penalties.
SpamKarma also aligns with assumptions made around Yandex penalizing hosts and individuals, as well as individual domains.
Onpage Advertising
There are a number of factors relating to advertising on the page, some of them deprecated (like the screenshot example below).
 Screenshot from author, January 2023
Screenshot from author, January 2023
It’s not known from the description exactly what the thought process with this factor was, but it could be assumed that a high ratio of adverts to visible screen was a negative factor – much like how Google takes umbrage if adverts obfuscate the page’s main content or are obtrusive.
Tying this back to known Yandex mechanisms, the Proxima update also took into consideration the ratio of useful and advertising content on a page.
Can We Apply Any Yandex Learnings To Google?
Yandex and Google are different search engines, with a number of differences, despite the tens of engineers who have worked for both companies.
Because of this fight for talent, we can infer that some of these master builders and engineers will have built things in a similar fashion (not direct copies), and applied learnings from previous iterations of their builds with their new employers.
What Russian SEOs Are Saying About The Leak
Much like the Western World, SEO professionals in Russia have been having their say on the leak across the various Runet forums.
The reaction in these forums has been different to SEO Twitter and Mastodon, with a focus more on Yandex’s filters, and other Yandex products that are optimized as part of wider Yandex optimization campaigns.
It is also worth noting that a number of conclusions and findings from the data match what the Western SEO world are also finding.
Common themes in the Russian search forums:
Webmasters asking for insights into recent filters, such as Mimicry and the updated PF filter. The age and relevance of some of the factors, due to author names no longer being at Yandex, and mentions of long-retired Yandex products. The main interesting learnings are around the use of Metrika data, and information relating to the Crawler & Indexer. A number of factors outline the usage of DSSM, which in theory was superseded by the release of Palekh in 2016. This was a search algorithm utilizing machine learning, announced by Yandex in 2016. A debate around ICS scoring in Yandex, and whether or not Yandex may provide more traffic to a site and influence its own factors by doing so.The leaked factors, particularly around how Yandex evaluates site quality have also come under scrutiny.
There is a long-standing sentiment in the Russian SEO community that Yandex oftentimes favors its own products and services in search results ahead of other websites, and webmasters are asking questions like:
Why do they bother going to all this trouble, when they just nail their services to the top of the page anyway?
In loosely translated documents, these are referred to as the Sorcerers or Yandex Sorcerers. In Google, we’d call these SERP (search engine results pages) features – like Google Hotels, etc
In October 2022, Kassir (a Russian ticket portal) claimed ₽328m compensation from Yandex due to lost revenue, caused by the “discriminatory conditions” in which Yandex Sorcerers took the customer base away from the private company.
This is off the back of a 2020 class action in which multiple companies raised a case with the FAS (Federal Antimonopoly Service) for anticompetitive promotion of their own services.
More resources:
Yandex Search Ranking Factors Leak: Insights 10 Biggest Differences Between Yandex & Google SEO The Ultimate Guide to Yandex SEOFeatured Image: /Shutterstock