Google’s Mixed Messages: Does Googlebot Really “Follow” Links? via @sejournal, @MattGSouthern
Google's Gary Illyes reveals Googlebot collects links instead of "following" them, contradicting official documentation. The post Google’s Mixed Messages: Does Googlebot Really “Follow” Links? appeared first on Search Engine Journal.
 Lynk
Lynk


Advertisement
Google's Gary Illyes reveals Googlebot collects links instead of "following" them, contradicting official documentation.
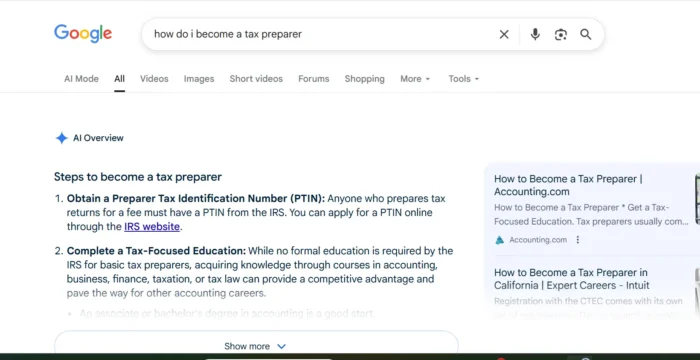
Googlebot collects links rather than following them in real-time. Gary Illyes shared this information in Google's 'Search Off The Record' podcast. Google's documentation contradicts the actual crawler behavior.In a recent episode of Google’s Search Off The Record podcast, Analyst Gary Illyes clarified how Googlebot interacts with links during the crawling process.
His insight contradicts the widely held belief that Googlebot navigates websites by following links in real-time.
According to Illyes, the Googlebot gathers links for later processing rather than following them in a linear fashion.
This misunderstanding stems from Google’s own documentation.
Contradictory Information
“It’s my pet peeve,” Illyes stated during the podcast, referring to Google’s support pages.
He continues:
“On our site, we keep saying Googlebot is following links, but no, it’s not following links. It’s collecting links, and then it goes back to those links.”
What The Documents Say
Google’s official documentation on crawlers states (emphasis mine):
“Crawler (sometimes also called a ‘robot’ or ‘spider’) is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.”
The document implies that Googlebot navigates the web by actively following links in real-time.
This highlights a discrepancy between Google’s public messaging and the actual functionality of their crawler, raising questions about other potential misunderstandings in the SEO community.
Implications For SEO
This revelation has several potential implications for how we understand Google’s crawling process:
Crawl Budget: If Googlebot collects links first and then revisits them later, it might impact how we think about crawl budgets. It’s possible that the initial “collection” phase might be less resource-intensive than previously thought. Site Architecture: While a logical site structure is important, the idea that Googlebot needs to “find” deep pages through a series of clicks may be outdated. This could influence how we approach internal linking and site depth. Crawl Frequency: This insight might explain why some pages are crawled more frequently than others, regardless of their position in the site hierarchy.Looking Ahead
Many SEO strategies are built on the assumption that Googlebot traverses websites by following internal links like a visitor on a page.
If Illyes’ description is accurate, it suggests that Googlebot’s behavior is more complex than previously understood.
While this revelation doesn’t invalidate current SEO best practices, it does highlight the need for SEO professionals to stay informed about the nuances of how Google operates.
Hear Illyes’ statement in the podcast below:
Featured Image: Ribkhan/Shutterstock
SEJ STAFF Matt G. Southern Senior News Writer at Search Engine Journal
Matt G. Southern, Senior News Writer, has been with Search Engine Journal since 2013. With a bachelor’s degree in communications, ...
![]()
Subscribe To Our Newsletter.
Conquer your day with daily search marketing news.









![7 Strategies That Will Get Powerful Results for Your Marketing and Sales Teams [Free Webinar on May 24th]](https://neilpatel.com/wp-content/uploads/2022/05/1362817_WEBINAR-7StrategiesThatWillGetPowerfulResultsForYourMarketingAndSalesTeams.jpg)
![Perfectly Optimized Content From Start to Finish [Ebook] via @sejournal, @duchessjenm](https://cdn.searchenginejournal.com/wp-content/uploads/2022/03/featured-no-cta-6220ba7f8f065-sej.jpg)