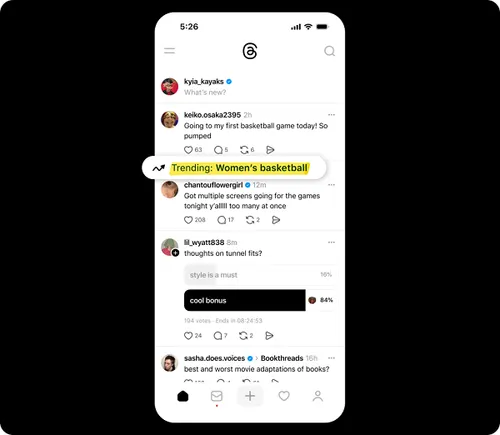
How to Fix “Discovered - currently not indexed”
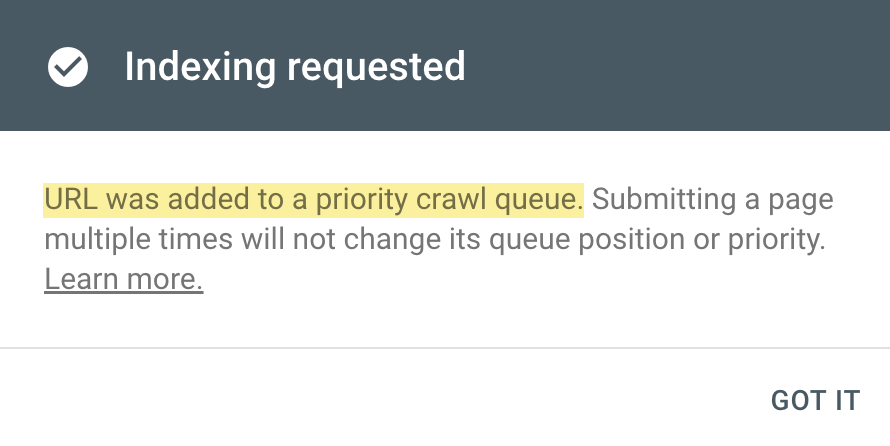
Follow this five-step process to diagnose and fix the issue. If you only see a few pages with the “Discovered - currently not indexed” issue, try requesting indexing via Google Search Console (GSC). To do that, click “URL inspection”...
 Koichiko
Koichiko

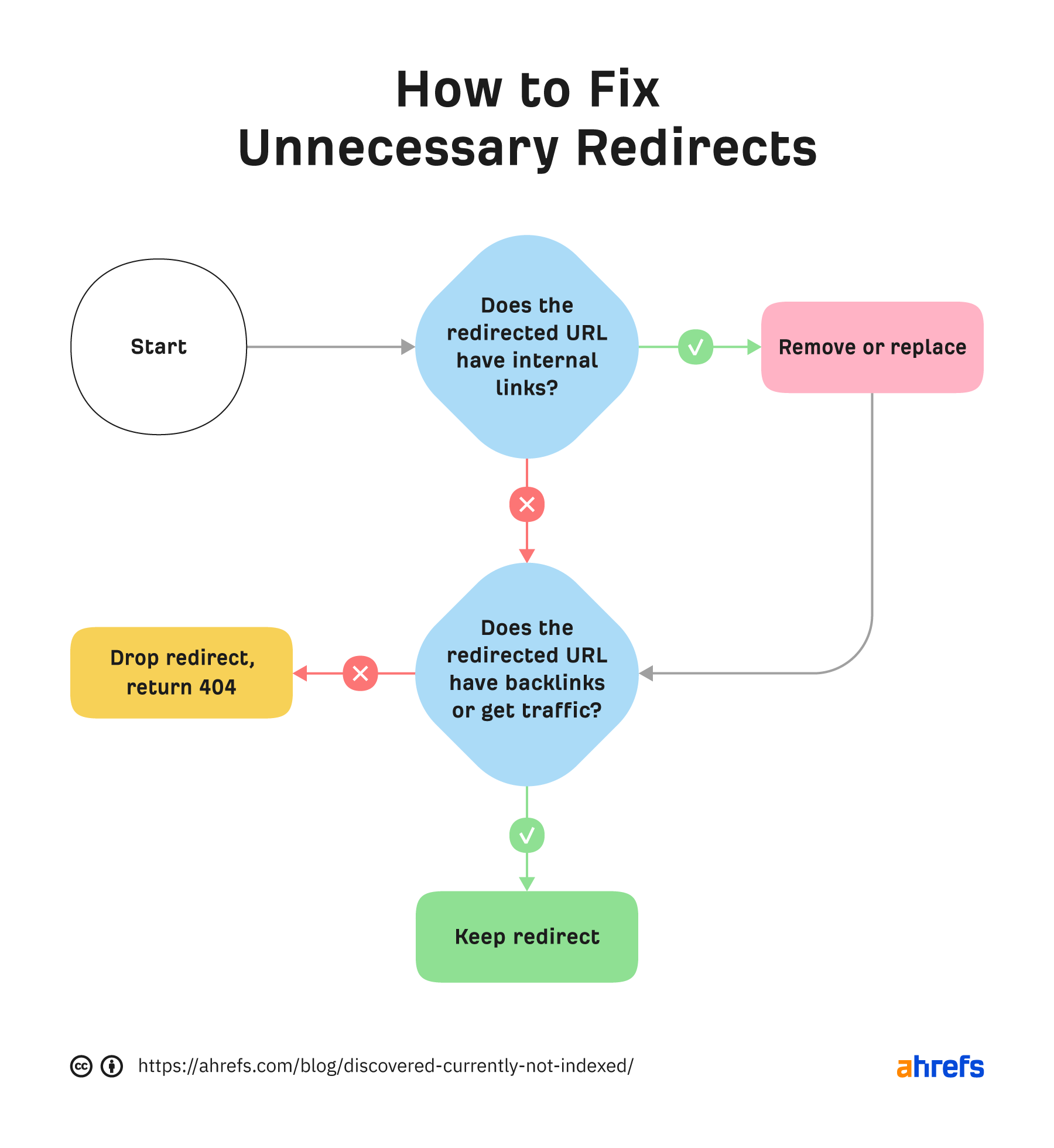
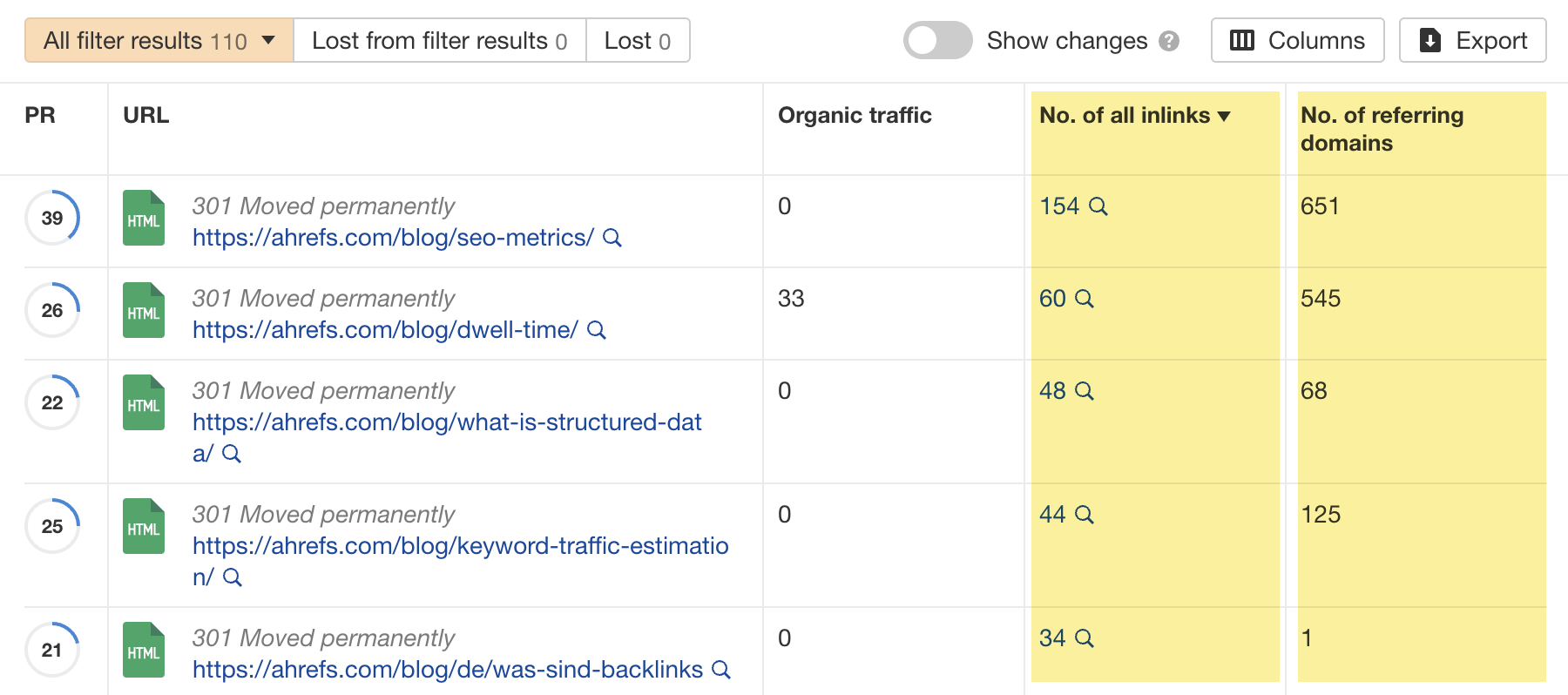
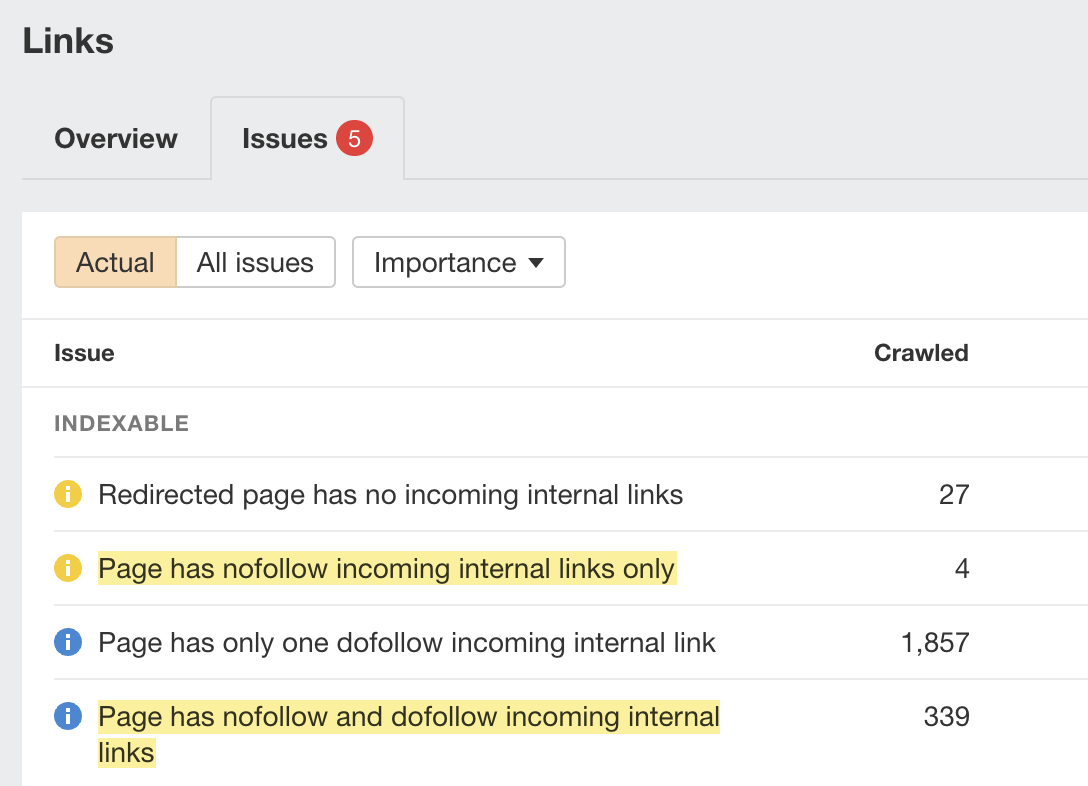
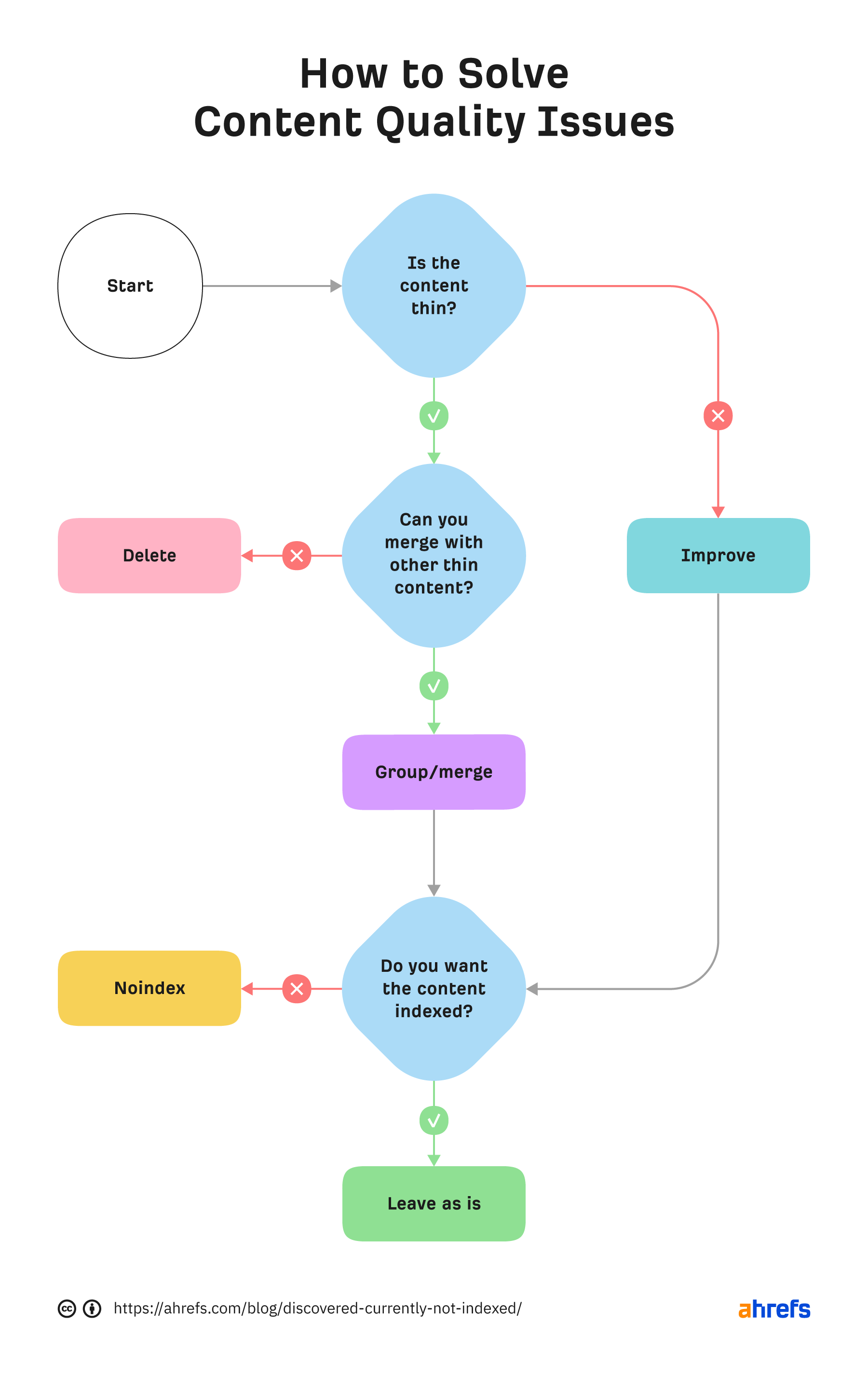
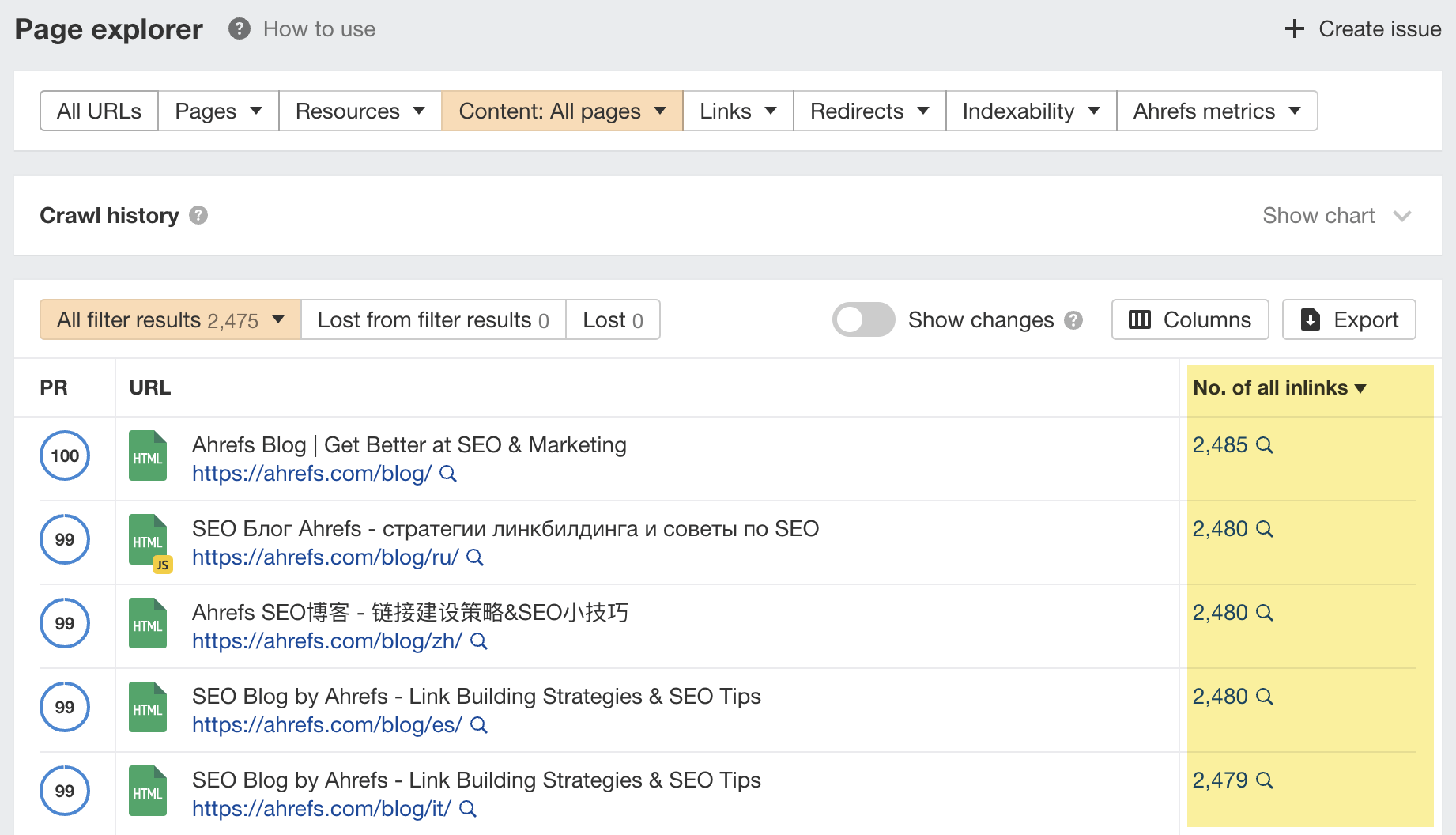
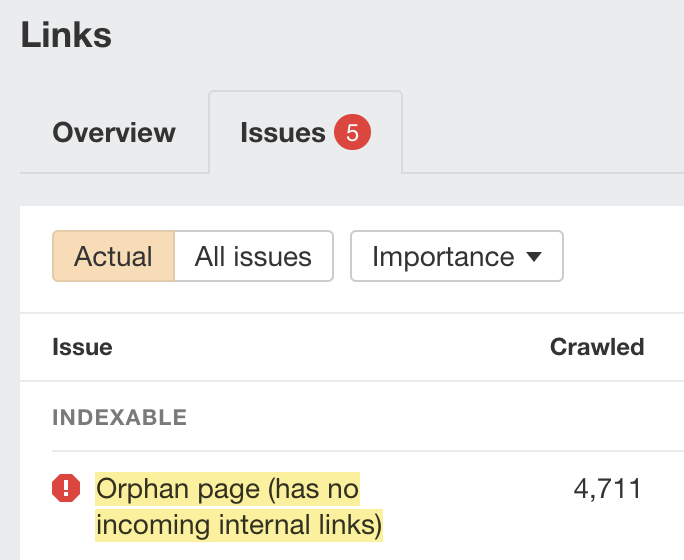
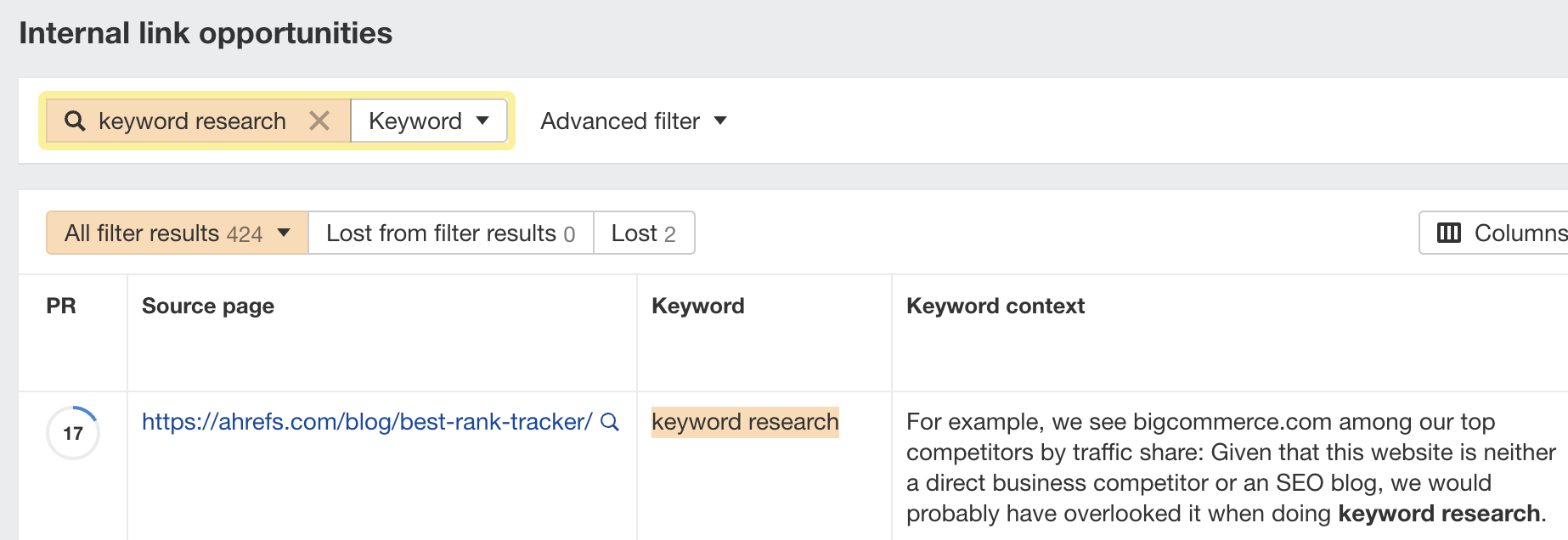
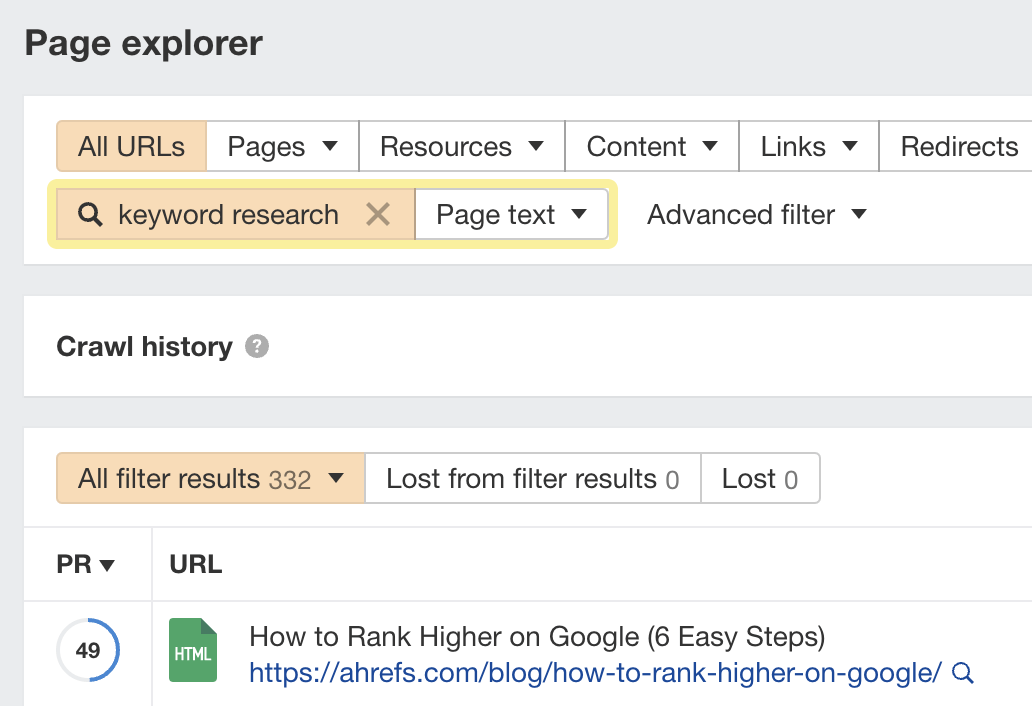
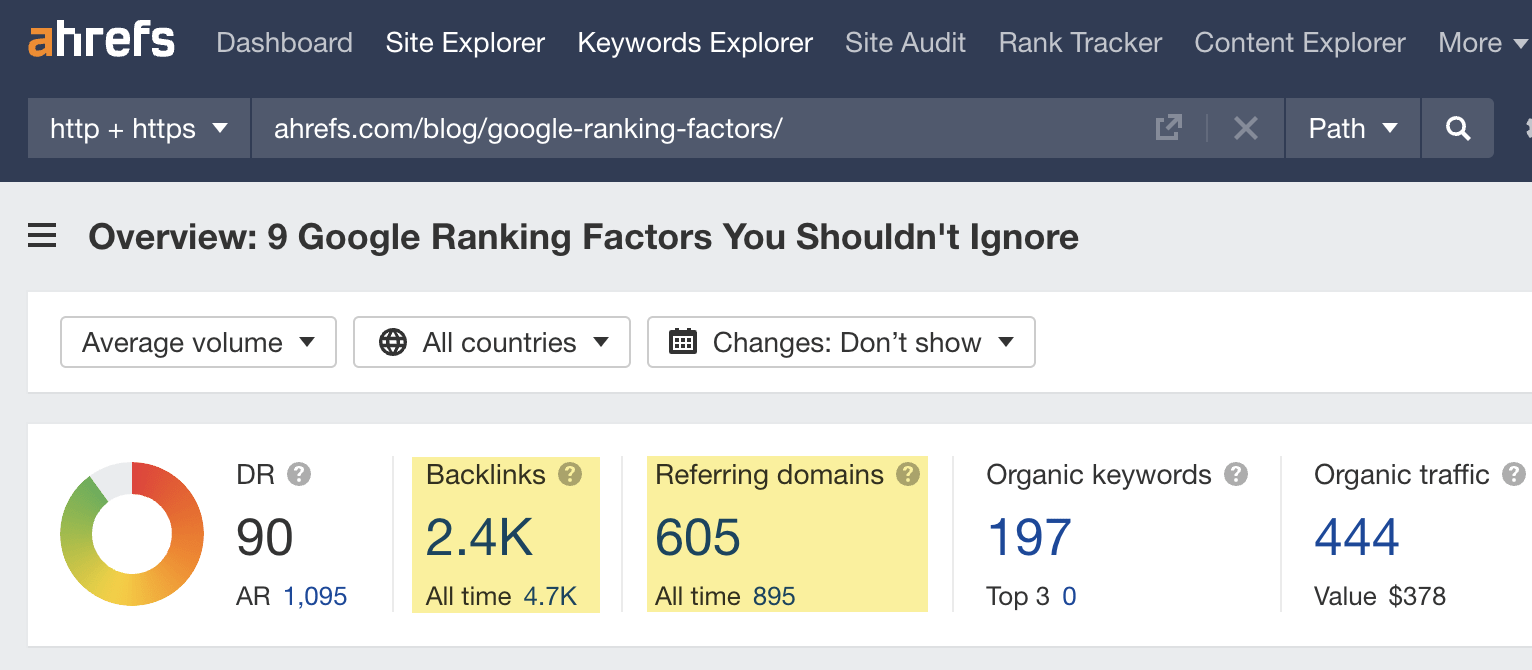
“Discovered - currently not indexed” means Google knows about the URL but hasn’t yet crawled or indexed it. Follow this five-step process to diagnose and fix the issue. If you only see a few pages with the “Discovered - currently not indexed” issue, try requesting indexing via Google Search Console (GSC). To do that, click “URL inspection” on the menu and enter the page’s URL. If it’s not currently indexed, hit the “Request indexing” button. If all is good, you should see a message that the URL was added to the priority crawl queue. Sidenote. There is a limit on how many URLs you can submit. While this is not defined in the docs, you can typically submit 10–15 URLs daily. If this doesn’t work, there’s almost always an underlying issue you need to diagnose and fix before requesting indexing for a second time. So keep reading. Crawl budget is how fast and how many pages a search engine wants to crawl on your site. If your crawlable URLs exceed your crawl budget, you may see the “Discovered - currently not indexed” warning. According to Google’s Gary Illyes, 90% of sites don’t need to worry about it. However, although issues with crawl budgets tend to affect larger sites, specific technical setups, problems, and mistakes can lead to issues on smaller sites. Let’s look at a few things that can lead to crawl budget issues and how to improve them. Let’s say your main website is on example.com, but you have assets on a subdomain such as cdn.example.com. In this case, the asset subdomain may be considered part of your main website and grouped together for the crawl budget. Consider serving assets from a CDN URL with a separate crawl budget to solve this. Typically, when we decide to remove a page from the website, we add a redirect to another relevant page. However, this isn’t always necessary. Unless the page has backlinks or traffic, it’s better to remove or replace internal links to the deleted page and return a 404. Here’s a flowchart explaining the process: You can find redirected URLs with internal and external links free of charge with an Ahrefs Webmaster Tools (AWT) account. Here’s the process: Duplicate content is when you have near or exact copies of pages accessible at multiple URLs. Examples include: The way you solve duplicate content issues depends on your circumstances. Learn more: Duplicate Content: Why It Happens and How to Fix It Nofollow links won’t prevent the page from being indexed. However, using them internally tells search engines a page is not important. Here’s how to find pages with nofollowed internal links for free using AWT: If the page is important, replace the nofollow links with followed ones. If the only way to discover your new page is from the sitemap and it has no internal links, Google may consider it unimportant. I’ll discuss this in more detail below when talking about internal linking. Google doesn’t index everything it discovers. It prioritizes high-quality, unique, and compelling content. As Google hasn’t yet crawled pages with this warning, it can’t know whether the content is low quality or not. However, it may have an idea based on similar pages that it’s already crawled—which is why it may have “deprioritized” crawling. Here are a few types of content Google is unlikely to index: If any of these apply to your content, use the flowchart below to fix the issue: In short, if you have thin content, merge it with other thin content to create something useful or delete it. Otherwise, improve the content. If the resulting content isn’t made for organic search, noindex it so search engines can prioritize crawling more important pages. Internal links are links from one page on your website to another. Google often sees URLs without any or many internal links as unimportant and may not index them. You can check if a URL has internal links for free with AWT. Here’s how: If you selected backlinks and/or sitemaps as URL sources when setting up your project, you may also be able to find some orphan pages. Just go to the Links report, click the “Issues” tab, and look for the “Orphan page (has no incoming internal links)” error. Recommendation Finding all the orphan pages on your website may not be possible with a crawling tool like Site Audit. This is because orphan pages have no internal links to crawl. You’ll have to check server logs for a complete picture. Learn how in our guide to finding orphan pages. You can also use Ahrefs to find internal linking opportunities between two existing pages. Here’s how: For example, let’s say Ahrefs wrote a post about keyword research. Entering “keyword research” finds pages on your site that mention that keyword and shows you the context. You can then add internal contextual links where relevant. Alternatively, you can search within the page text using Page Explorer to find potential pages to link from when you are publishing a new page. However, none of these tactics can replace a good website structure with logical internal linking. That’s something every site should prioritize. However, if you’re facing issues, one way is to “hack” your crawl depth and ensure all your internal pages are linked from an HTML sitemap. An HTML sitemap is an HTML page that gives users a better picture of your website structure and an easier way to navigate. Unlike XML sitemaps, which are made to be parsed by different systems, HTML sitemaps are made for users. While they’re sometimes considered a thing of the past, they are still relevant. If you have a big website, you may want to consider splitting it into a logical structure, as you don’t want tens of thousands of URLs linked to from a single page. Check out how LinkedIn does it for inspiration. Recommendation Ensure you use proper <a> tags for the internal links instead of using JavaScript functions such as onClick() to lead the user to another page. If you’re using Jamstack or a JS framework, check how it, or some of its libraries, handles internal links. They need to be rendered as <a> tags. Backlinks are one of the signals Google uses to decide whether a page is likely to be valuable and worthy of crawling. If your page has no or few high-quality backlinks, it may be one of the reasons Google has “deprioritized” crawling. Getting more backlinks is probably the hardest of all the listed, but it does pay off. Even one valuable link can help Google discover your content and index it faster. You can see how many backlinks any page on your website has for free with AWT. If you want to check a specific page, paste it into Ahrefs’ Site Explorer and check the Overview report. If you want to see which pages do or don’t have many backlinks, enter your domain into Site Explorer and check the Best by links report. If an important page has few or no backlinks, consider trying to build more.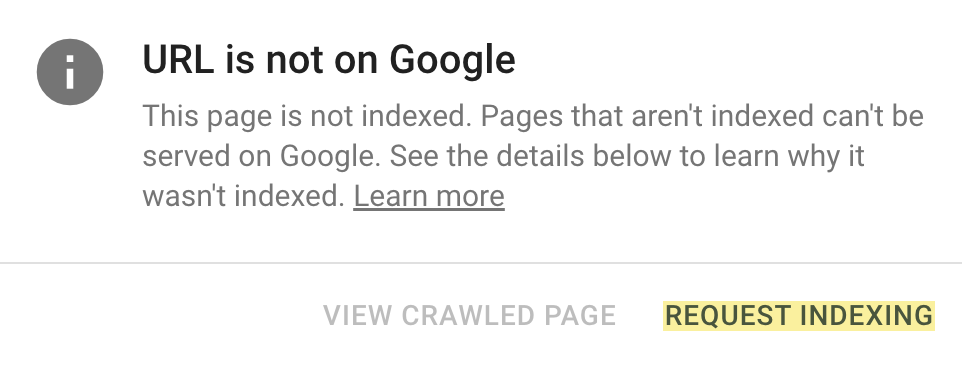
Do you serve content from subdomains?
Do you have unnecessary redirects?
Do you have duplicate content?
Have you used internal nofollow links?
Do you have orphan pages?
Keep learning
Google’s New Search Console URL Inspection API: What It Is & How to Use ItHow to Fix “indexed, though blocked by robots.txt” in GSC